One-Shot Object Affordance Detection in the Wild
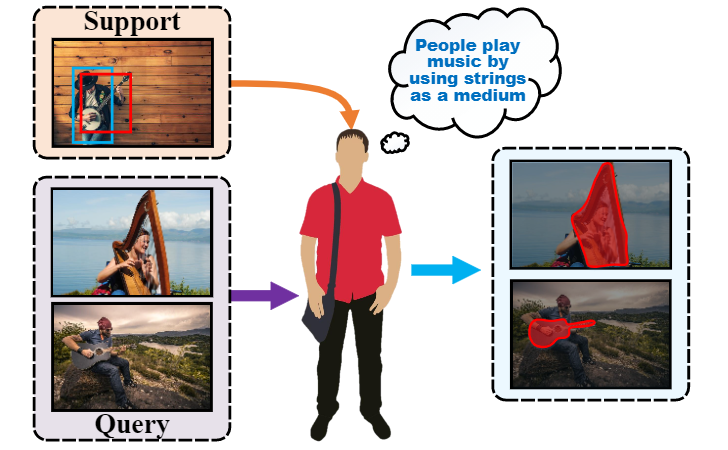
Affordance detection refers to identifying the potential action possibilities of objects in an image, which is a crucial ability for robot perception and manipulation. To empower robots with this ability in unseen scenarios, we first study the challenging one-shot affordance detection problem in this paper, i.e., given a support image that depicts the action purpose, all objects in a scene with the common affordance should be detected. To this end, we devise a One-Shot Affordance Detection Network (OSAD-Net) that firstly estimates the human action purpose and then transfers it to help detect the common affordance from all candidate images. Through collaboration learning, OSAD-Net can capture the common characteristics between objects having the same underlying affordance and learn a good adaptation capability for perceiving unseen affordances. Besides, we build a large-scale Purpose-driven Affordance Dataset v2 (PADv2) by collecting and labeling 30k images from 39 affordance and 103 object categories. With complex scenes and rich annotations, our PADv2 dataset can be used as a test bed to benchmark affordance detection methods and may also facilitate downstream vision tasks, such as scene understanding, action recognition, and robot manipulation. Specifically, we conducted comprehensive experiments on PADv2 dataset by including 11 advanced models from several related research fields. Experimental results demonstrate the superiority of our model over previous representative ones in terms of both objective metrics and visual quality. The benchmark suite is available at https://github.com/lhc1224/OSAD Net.
PDF Abstract



 PADv2
PADv2
 MS COCO
MS COCO
 3D AffordanceNet
3D AffordanceNet
 PAD
PAD
