Online Double Oracle
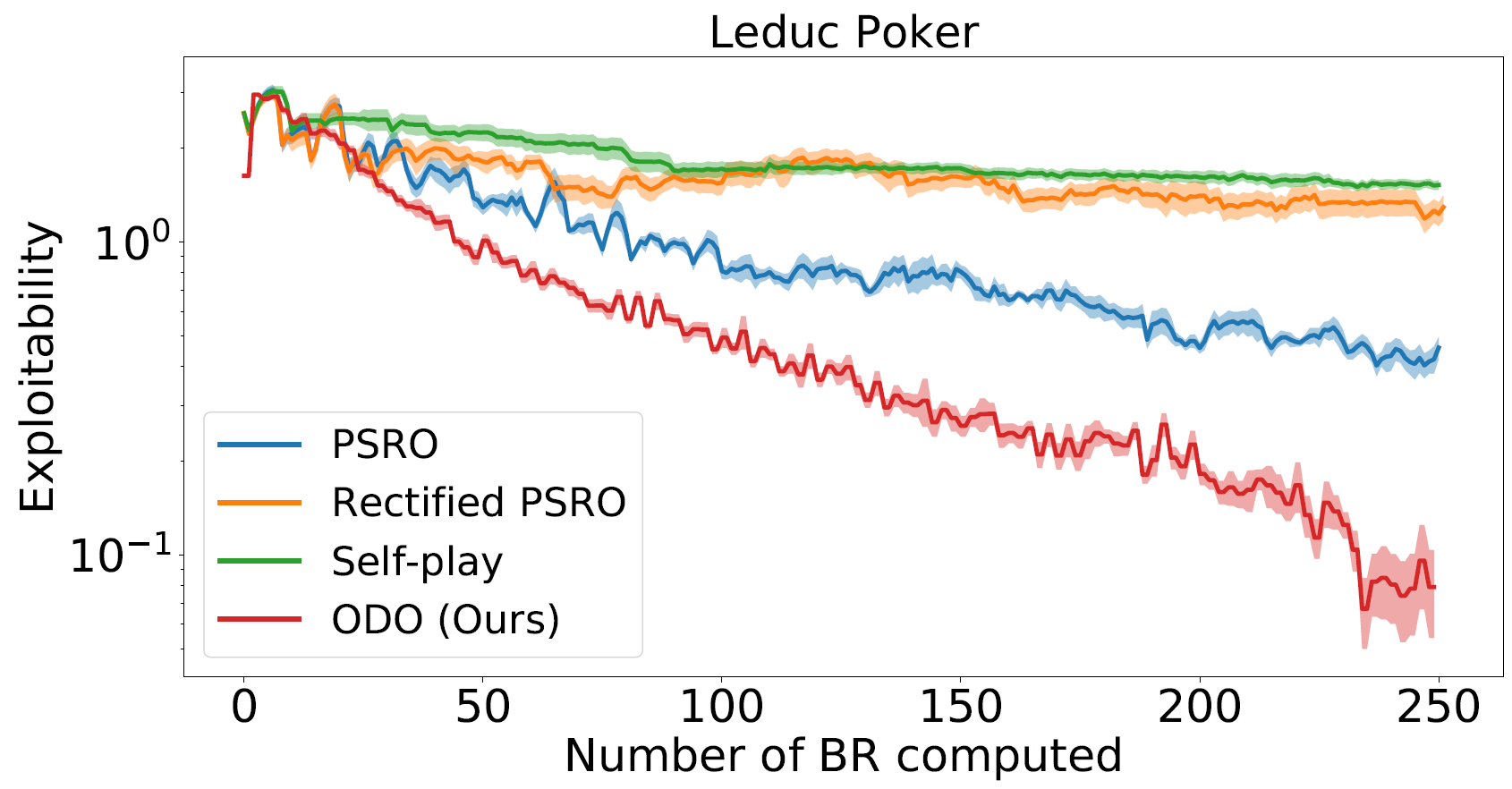
Solving strategic games with huge action space is a critical yet under-explored topic in economics, operations research and artificial intelligence. This paper proposes new learning algorithms for solving two-player zero-sum normal-form games where the number of pure strategies is prohibitively large. Specifically, we combine no-regret analysis from online learning with Double Oracle (DO) methods from game theory. Our method -- \emph{Online Double Oracle (ODO)} -- is provably convergent to a Nash equilibrium (NE). Most importantly, unlike normal DO methods, ODO is \emph{rationale} in the sense that each agent in ODO can exploit strategic adversary with a regret bound of $\mathcal{O}(\sqrt{T k \log(k)})$ where $k$ is not the total number of pure strategies, but rather the size of \emph{effective strategy set} that is linearly dependent on the support size of the NE. On tens of different real-world games, ODO outperforms DO, PSRO methods, and no-regret algorithms such as Multiplicative Weight Update by a significant margin, both in terms of convergence rate to a NE and average payoff against strategic adversaries.
PDF Abstract