OpenMEVA: A Benchmark for Evaluating Open-ended Story Generation Metrics
Automatic metrics are essential for developing natural language generation (NLG) models, particularly for open-ended language generation tasks such as story generation. However, existing automatic metrics are observed to correlate poorly with human evaluation. The lack of standardized benchmark datasets makes it difficult to fully evaluate the capabilities of a metric and fairly compare different metrics. Therefore, we propose OpenMEVA, a benchmark for evaluating open-ended story generation metrics. OpenMEVA provides a comprehensive test suite to assess the capabilities of metrics, including (a) the correlation with human judgments, (b) the generalization to different model outputs and datasets, (c) the ability to judge story coherence, and (d) the robustness to perturbations. To this end, OpenMEVA includes both manually annotated stories and auto-constructed test examples. We evaluate existing metrics on OpenMEVA and observe that they have poor correlation with human judgments, fail to recognize discourse-level incoherence, and lack inferential knowledge (e.g., causal order between events), the generalization ability and robustness. Our study presents insights for developing NLG models and metrics in further research.
PDF Abstract ACL 2021 PDF ACL 2021 Abstract


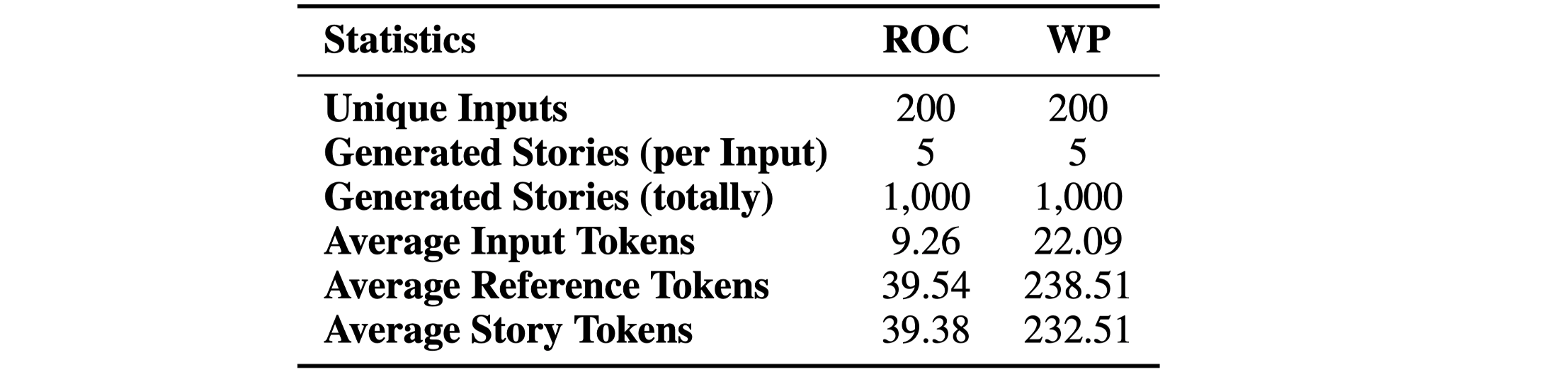
 OpenMEVA
OpenMEVA
 ROCStories
ROCStories
