Perceiver: General Perception with Iterative Attention
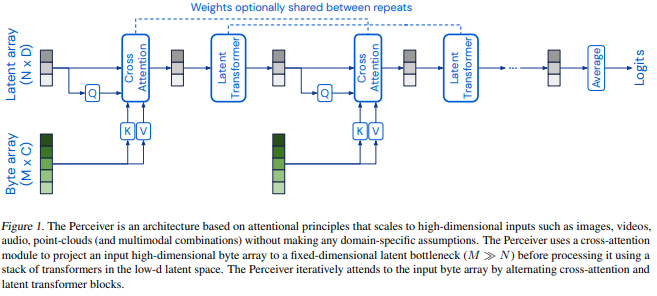
Biological systems perceive the world by simultaneously processing high-dimensional inputs from modalities as diverse as vision, audition, touch, proprioception, etc. The perception models used in deep learning on the other hand are designed for individual modalities, often relying on domain-specific assumptions such as the local grid structures exploited by virtually all existing vision models. These priors introduce helpful inductive biases, but also lock models to individual modalities. In this paper we introduce the Perceiver - a model that builds upon Transformers and hence makes few architectural assumptions about the relationship between its inputs, but that also scales to hundreds of thousands of inputs, like ConvNets. The model leverages an asymmetric attention mechanism to iteratively distill inputs into a tight latent bottleneck, allowing it to scale to handle very large inputs. We show that this architecture is competitive with or outperforms strong, specialized models on classification tasks across various modalities: images, point clouds, audio, video, and video+audio. The Perceiver obtains performance comparable to ResNet-50 and ViT on ImageNet without 2D convolutions by directly attending to 50,000 pixels. It is also competitive in all modalities in AudioSet.
PDF Abstract

 Colab
Colab




 ImageNet
ImageNet
 ModelNet
ModelNet
 AudioSet
AudioSet

