PersonLab: Person Pose Estimation and Instance Segmentation with a Bottom-Up, Part-Based, Geometric Embedding Model
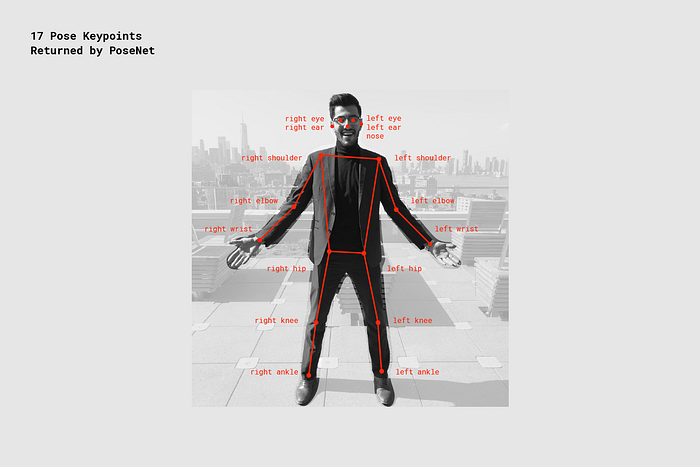
We present a box-free bottom-up approach for the tasks of pose estimation and instance segmentation of people in multi-person images using an efficient single-shot model. The proposed PersonLab model tackles both semantic-level reasoning and object-part associations using part-based modeling. Our model employs a convolutional network which learns to detect individual keypoints and predict their relative displacements, allowing us to group keypoints into person pose instances. Further, we propose a part-induced geometric embedding descriptor which allows us to associate semantic person pixels with their corresponding person instance, delivering instance-level person segmentations. Our system is based on a fully-convolutional architecture and allows for efficient inference, with runtime essentially independent of the number of people present in the scene. Trained on COCO data alone, our system achieves COCO test-dev keypoint average precision of 0.665 using single-scale inference and 0.687 using multi-scale inference, significantly outperforming all previous bottom-up pose estimation systems. We are also the first bottom-up method to report competitive results for the person class in the COCO instance segmentation task, achieving a person category average precision of 0.417.
PDF Abstract ECCV 2018 PDF ECCV 2018 Abstract





 MS COCO
MS COCO

