PiPa: Pixel- and Patch-wise Self-supervised Learning for Domain Adaptative Semantic Segmentation
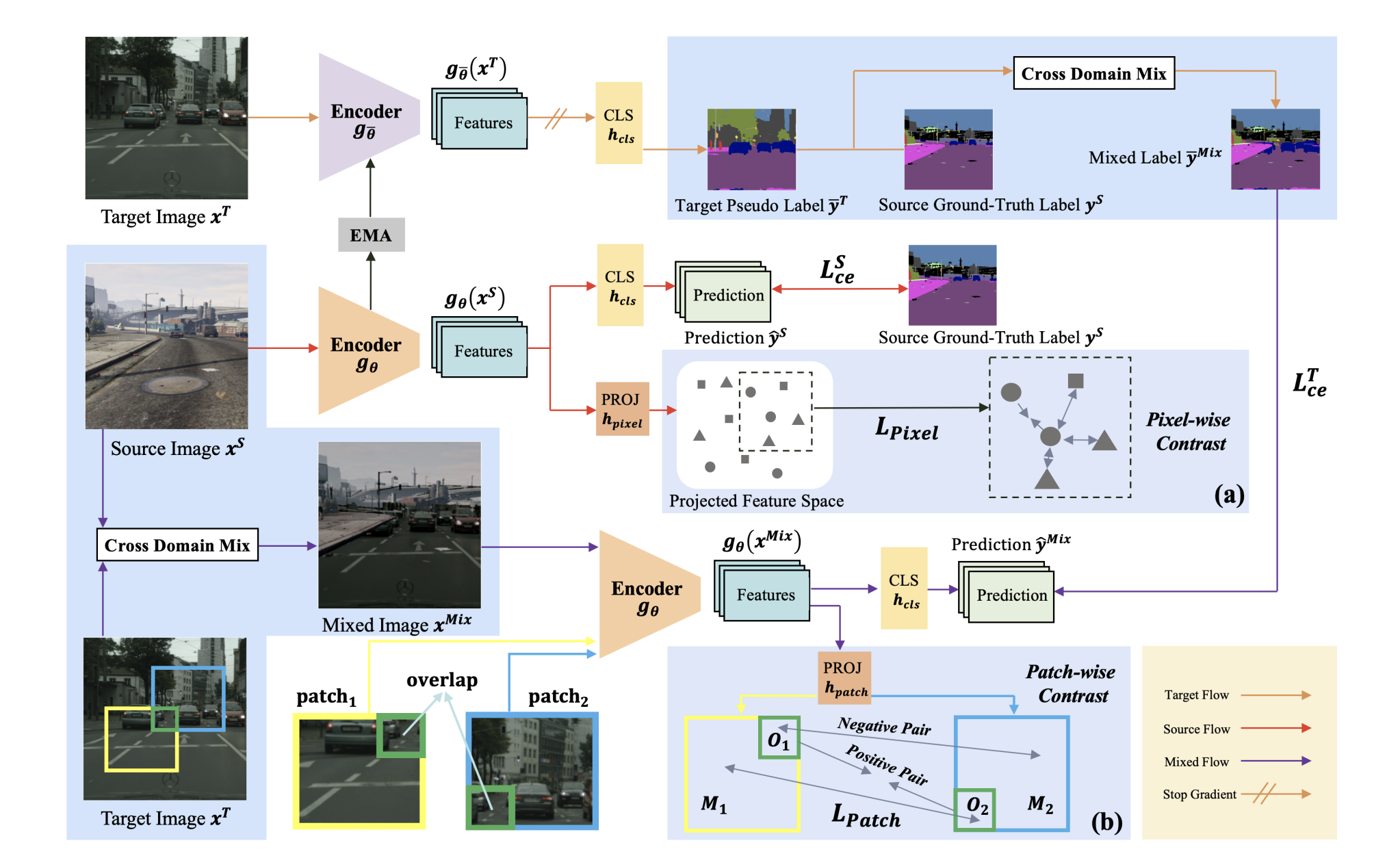
Unsupervised Domain Adaptation (UDA) aims to enhance the generalization of the learned model to other domains. The domain-invariant knowledge is transferred from the model trained on labeled source domain, e.g., video game, to unlabeled target domains, e.g., real-world scenarios, saving annotation expenses. Existing UDA methods for semantic segmentation usually focus on minimizing the inter-domain discrepancy of various levels, e.g., pixels, features, and predictions, for extracting domain-invariant knowledge. However, the primary intra-domain knowledge, such as context correlation inside an image, remains underexplored. In an attempt to fill this gap, we propose a unified pixel- and patch-wise self-supervised learning framework, called PiPa, for domain adaptive semantic segmentation that facilitates intra-image pixel-wise correlations and patch-wise semantic consistency against different contexts. The proposed framework exploits the inherent structures of intra-domain images, which: (1) explicitly encourages learning the discriminative pixel-wise features with intra-class compactness and inter-class separability, and (2) motivates the robust feature learning of the identical patch against different contexts or fluctuations. Extensive experiments verify the effectiveness of the proposed method, which obtains competitive accuracy on the two widely-used UDA benchmarks, i.e., 75.6 mIoU on GTA to Cityscapes and 68.2 mIoU on Synthia to Cityscapes. Moreover, our method is compatible with other UDA approaches to further improve the performance without introducing extra parameters.
PDF Abstract






 ImageNet
ImageNet
 SYNTHIA
SYNTHIA
 GTA5
GTA5

