PIQA: Reasoning about Physical Commonsense in Natural Language
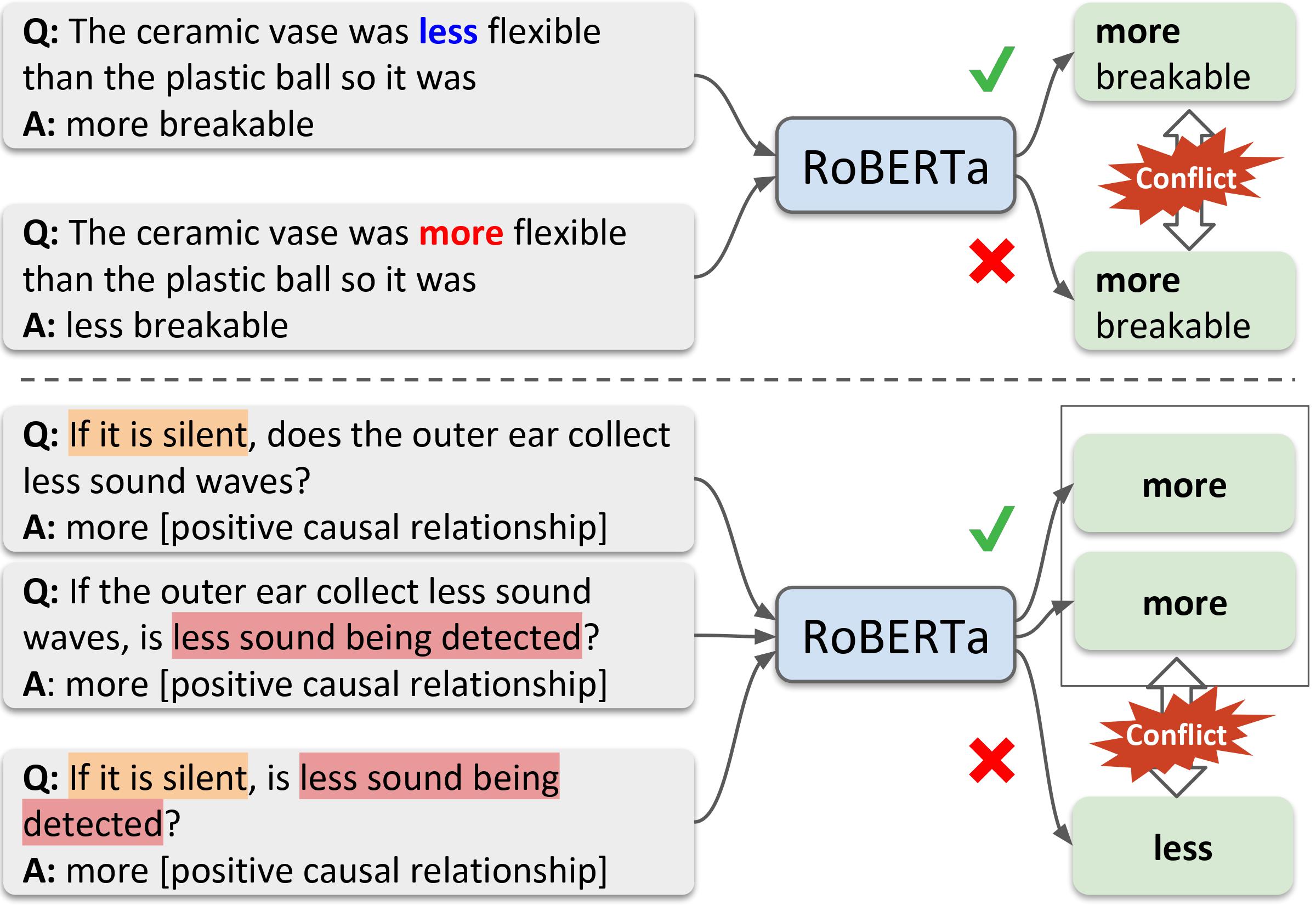
To apply eyeshadow without a brush, should I use a cotton swab or a toothpick? Questions requiring this kind of physical commonsense pose a challenge to today's natural language understanding systems. While recent pretrained models (such as BERT) have made progress on question answering over more abstract domains - such as news articles and encyclopedia entries, where text is plentiful - in more physical domains, text is inherently limited due to reporting bias. Can AI systems learn to reliably answer physical common-sense questions without experiencing the physical world? In this paper, we introduce the task of physical commonsense reasoning and a corresponding benchmark dataset Physical Interaction: Question Answering or PIQA. Though humans find the dataset easy (95% accuracy), large pretrained models struggle (77%). We provide analysis about the dimensions of knowledge that existing models lack, which offers significant opportunities for future research.
PDF AbstractCode



Datasets
Introduced in the Paper:
 PIQA
PIQA

