Polysemous Visual-Semantic Embedding for Cross-Modal Retrieval
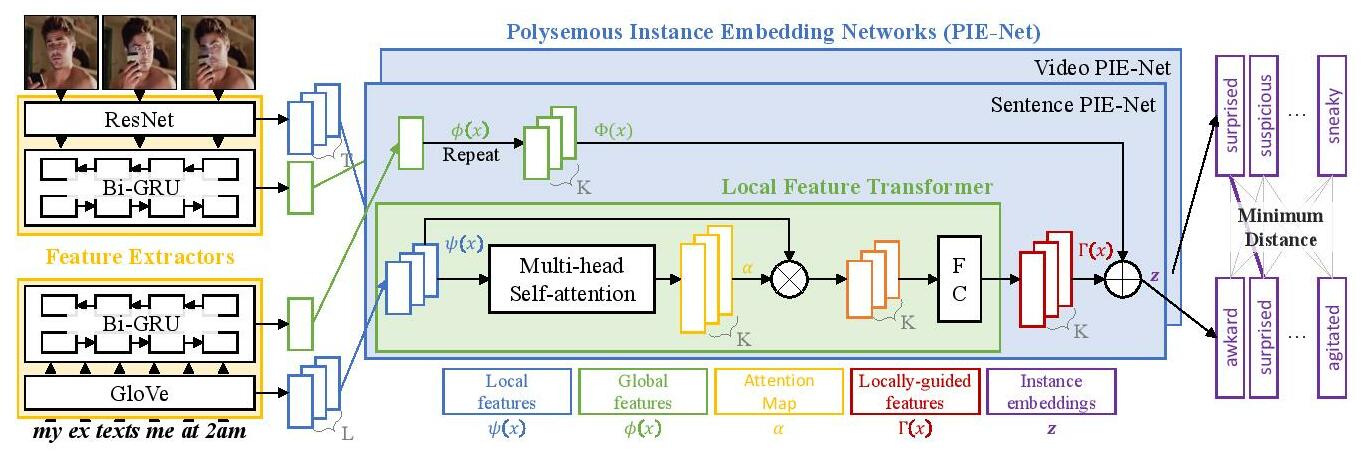
Visual-semantic embedding aims to find a shared latent space where related visual and textual instances are close to each other. Most current methods learn injective embedding functions that map an instance to a single point in the shared space. Unfortunately, injective embedding cannot effectively handle polysemous instances with multiple possible meanings; at best, it would find an average representation of different meanings. This hinders its use in real-world scenarios where individual instances and their cross-modal associations are often ambiguous. In this work, we introduce Polysemous Instance Embedding Networks (PIE-Nets) that compute multiple and diverse representations of an instance by combining global context with locally-guided features via multi-head self-attention and residual learning. To learn visual-semantic embedding, we tie-up two PIE-Nets and optimize them jointly in the multiple instance learning framework. Most existing work on cross-modal retrieval focuses on image-text data. Here, we also tackle a more challenging case of video-text retrieval. To facilitate further research in video-text retrieval, we release a new dataset of 50K video-sentence pairs collected from social media, dubbed MRW (my reaction when). We demonstrate our approach on both image-text and video-text retrieval scenarios using MS-COCO, TGIF, and our new MRW dataset.
PDF Abstract CVPR 2019 PDF CVPR 2019 Abstract

 MS COCO
MS COCO
 TGIF
TGIF

