Posterior Sampling for Reinforcement Learning Without Episodes
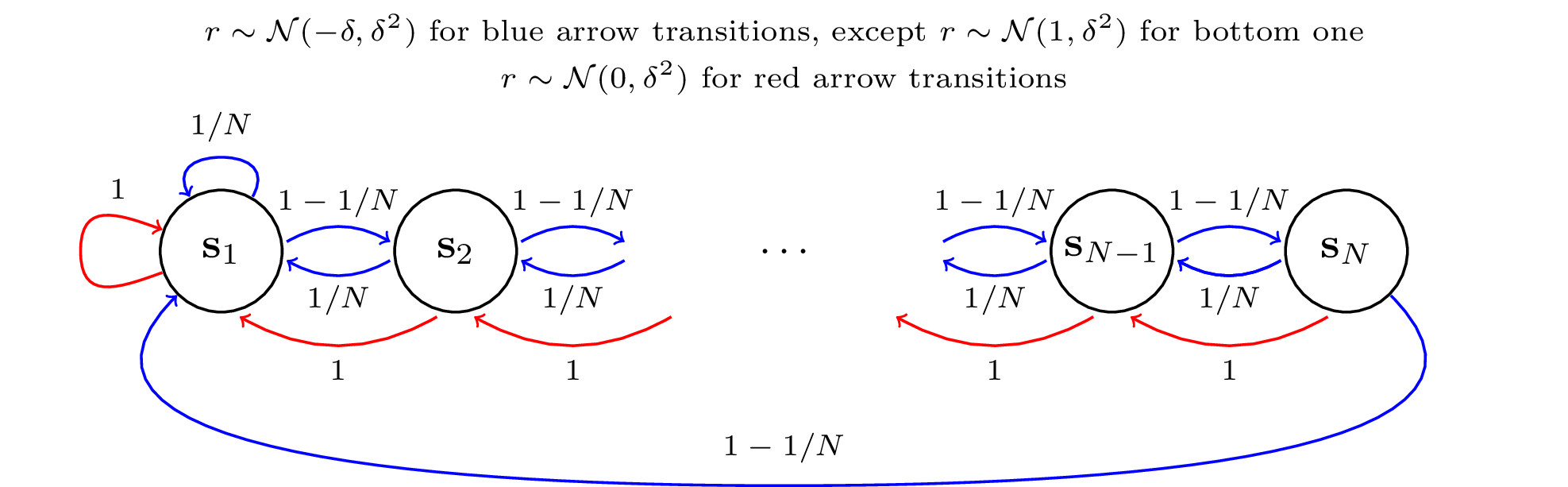
This is a brief technical note to clarify some of the issues with applying the application of the algorithm posterior sampling for reinforcement learning (PSRL) in environments without fixed episodes. In particular, this paper aims to: - Review some of results which have been proven for finite horizon MDPs (Osband et al 2013, 2014a, 2014b, 2016) and also for MDPs with finite ergodic structure (Gopalan et al 2014). - Review similar results for optimistic algorithms in infinite horizon problems (Jaksch et al 2010, Bartlett and Tewari 2009, Abbasi-Yadkori and Szepesvari 2011), with particular attention to the dynamic episode growth. - Highlight the delicate technical issue which has led to a fault in the proof of the lazy-PSRL algorithm (Abbasi-Yadkori and Szepesvari 2015). We present an explicit counterexample to this style of argument. Therefore, we suggest that the Theorem 2 in (Abbasi-Yadkori and Szepesvari 2015) be instead considered a conjecture, as it has no rigorous proof. - Present pragmatic approaches to apply PSRL in infinite horizon problems. We conjecture that, under some additional assumptions, it will be possible to obtain bounds $O( \sqrt{T} )$ even without episodic reset. We hope that this note serves to clarify existing results in the field of reinforcement learning and provides interesting motivation for future work.
PDF Abstract
