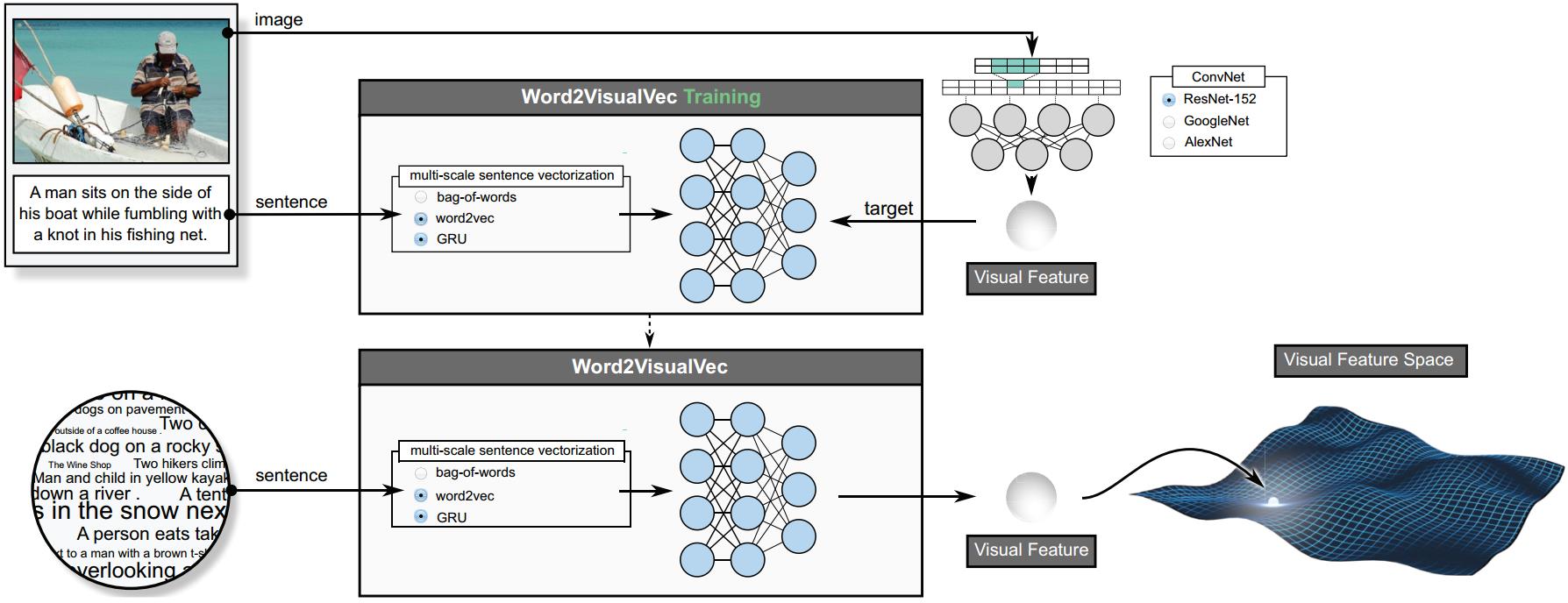
Predicting Visual Features from Text for Image and Video Caption Retrieval
This paper strives to find amidst a set of sentences the one best describing the content of a given image or video. Different from existing works, which rely on a joint subspace for their image and video caption retrieval, we propose to do so in a visual space exclusively. Apart from this conceptual novelty, we contribute \emph{Word2VisualVec}, a deep neural network architecture that learns to predict a visual feature representation from textual input. Example captions are encoded into a textual embedding based on multi-scale sentence vectorization and further transferred into a deep visual feature of choice via a simple multi-layer perceptron. We further generalize Word2VisualVec for video caption retrieval, by predicting from text both 3-D convolutional neural network features as well as a visual-audio representation. Experiments on Flickr8k, Flickr30k, the Microsoft Video Description dataset and the very recent NIST TrecVid challenge for video caption retrieval detail Word2VisualVec's properties, its benefit over textual embeddings, the potential for multimodal query composition and its state-of-the-art results.
PDF Abstract

 Flickr30k
Flickr30k
 MSVD
MSVD
