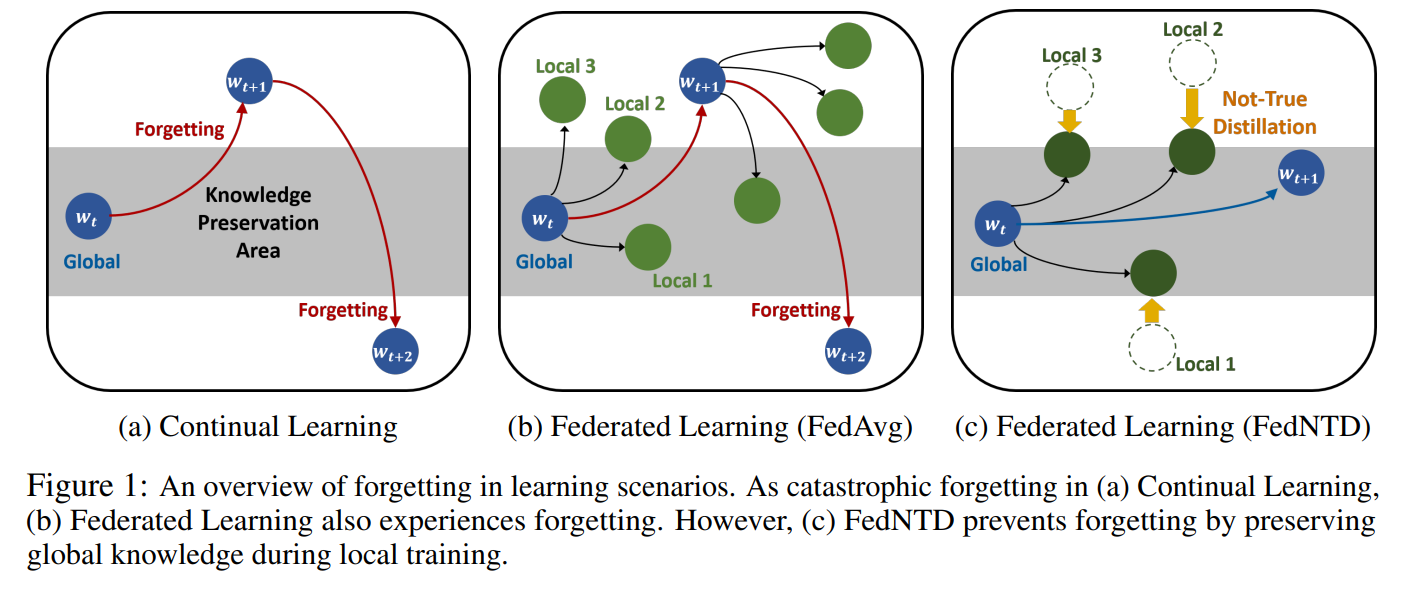
Preservation of the Global Knowledge by Not-True Distillation in Federated Learning
In federated learning, a strong global model is collaboratively learned by aggregating clients' locally trained models. Although this precludes the need to access clients' data directly, the global model's convergence often suffers from data heterogeneity. This study starts from an analogy to continual learning and suggests that forgetting could be the bottleneck of federated learning. We observe that the global model forgets the knowledge from previous rounds, and the local training induces forgetting the knowledge outside of the local distribution. Based on our findings, we hypothesize that tackling down forgetting will relieve the data heterogeneity problem. To this end, we propose a novel and effective algorithm, Federated Not-True Distillation (FedNTD), which preserves the global perspective on locally available data only for the not-true classes. In the experiments, FedNTD shows state-of-the-art performance on various setups without compromising data privacy or incurring additional communication costs.
PDF Abstract


 CIFAR-10
CIFAR-10
 CIFAR-100
CIFAR-100
 MNIST
MNIST
 CINIC-10
CINIC-10
