Pretrained Transformers Improve Out-of-Distribution Robustness
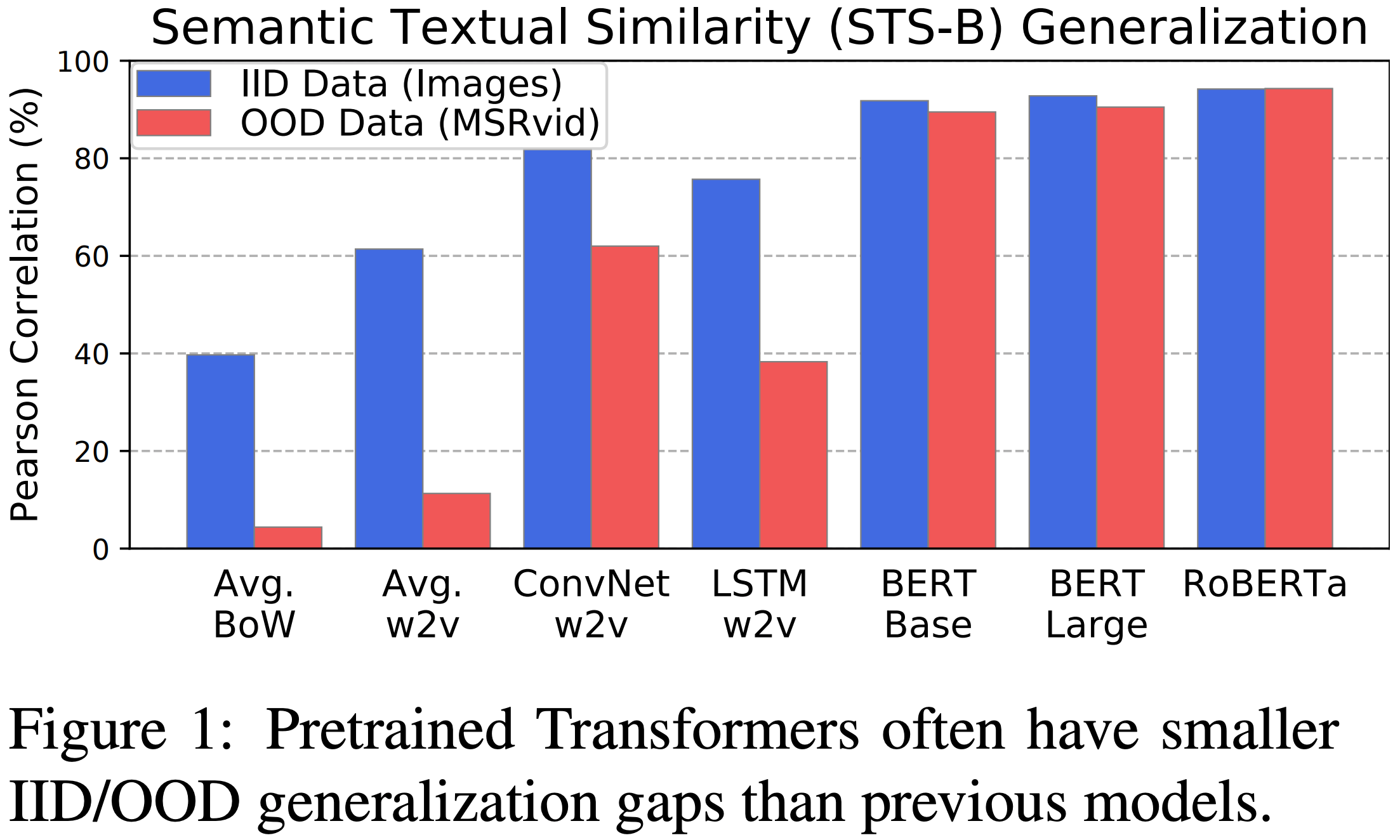
Although pretrained Transformers such as BERT achieve high accuracy on in-distribution examples, do they generalize to new distributions? We systematically measure out-of-distribution (OOD) generalization for seven NLP datasets by constructing a new robustness benchmark with realistic distribution shifts. We measure the generalization of previous models including bag-of-words models, ConvNets, and LSTMs, and we show that pretrained Transformers' performance declines are substantially smaller. Pretrained transformers are also more effective at detecting anomalous or OOD examples, while many previous models are frequently worse than chance. We examine which factors affect robustness, finding that larger models are not necessarily more robust, distillation can be harmful, and more diverse pretraining data can enhance robustness. Finally, we show where future work can improve OOD robustness.
PDF Abstract ACL 2020 PDF ACL 2020 Abstract
 SST
SST
 MultiNLI
MultiNLI
 IMDb Movie Reviews
IMDb Movie Reviews
 SNLI
SNLI
 ReCoRD
ReCoRD
