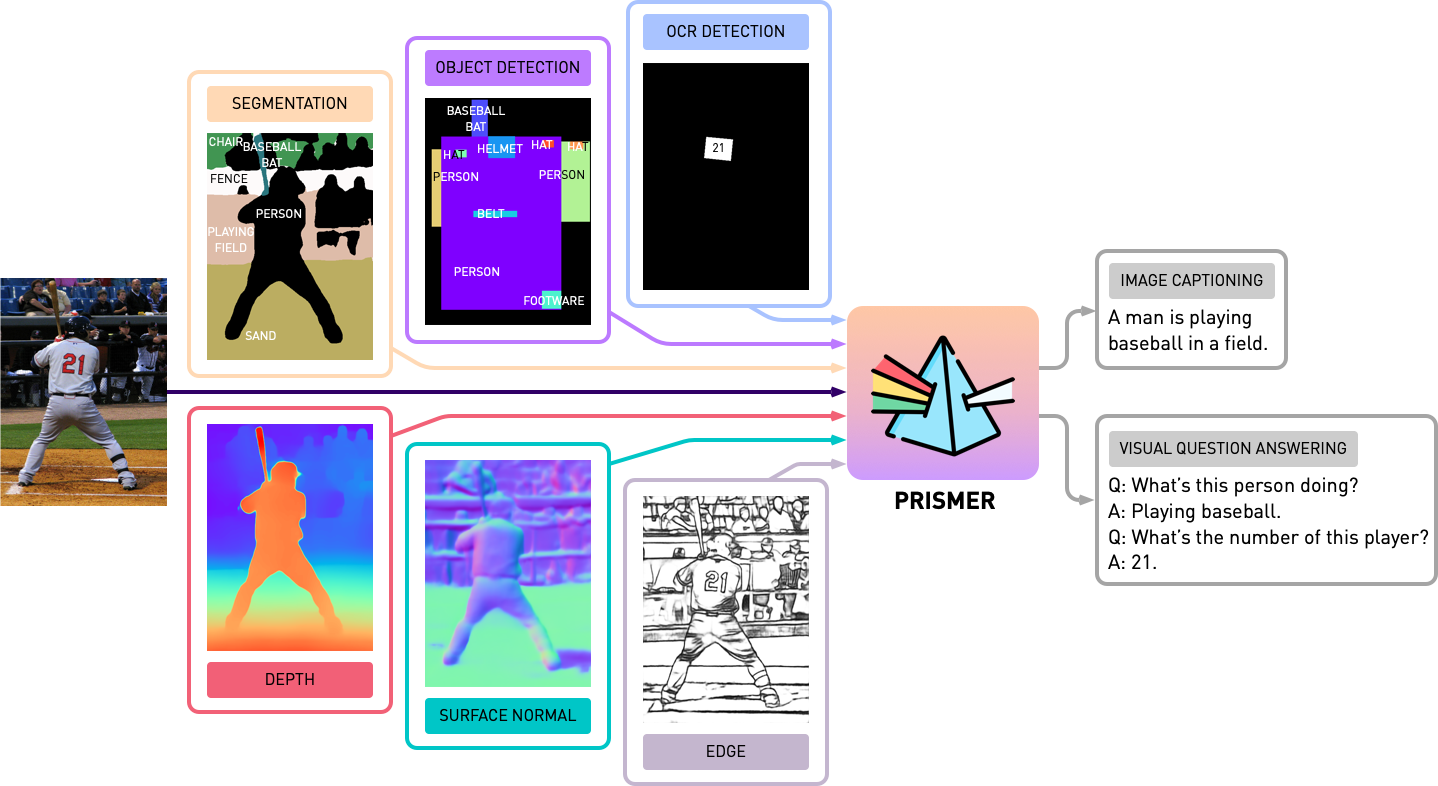
Prismer: A Vision-Language Model with Multi-Task Experts
Recent vision-language models have shown impressive multi-modal generation capabilities. However, typically they require training huge models on massive datasets. As a more scalable alternative, we introduce Prismer, a data- and parameter-efficient vision-language model that leverages an ensemble of task-specific experts. Prismer only requires training of a small number of components, with the majority of network weights inherited from multiple readily-available, pre-trained experts, and kept frozen during training. By leveraging experts from a wide range of domains, we show Prismer can efficiently pool this expert knowledge and adapt it to various vision-language reasoning tasks. In our experiments, we show that Prismer achieves fine-tuned and few-shot learning performance which is competitive with current state-of-the-arts, whilst requiring up to two orders of magnitude less training data. Code is available at https://github.com/NVlabs/prismer.
PDF Abstract Spaces
Spaces
 Replicate
Replicate





 MS COCO
MS COCO
 Visual Question Answering
Visual Question Answering
 Visual Genome
Visual Genome
 Visual Question Answering v2.0
Visual Question Answering v2.0
 Conceptual Captions
Conceptual Captions
 TextVQA
TextVQA
 COCO Captions
COCO Captions
 NoCaps
NoCaps
 VSR
VSR

