ProGen: Progressive Zero-shot Dataset Generation via In-context Feedback
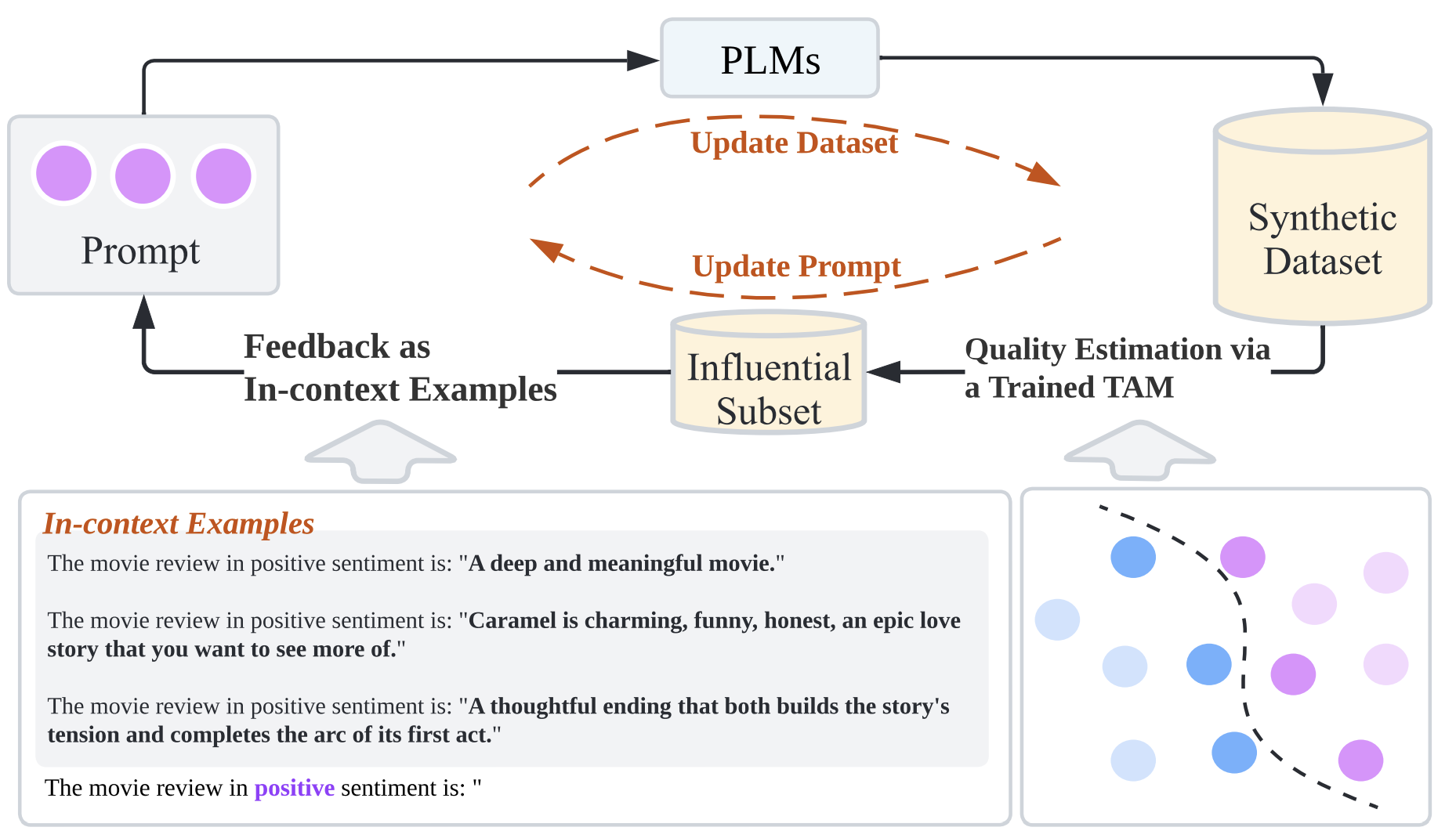
Recently, dataset-generation-based zero-shot learning has shown promising results by training a task-specific model with a dataset synthesized from large pre-trained language models (PLMs). The final task-specific model often achieves compatible or even better performance than PLMs under the zero-shot setting, with orders of magnitude fewer parameters. However, synthetic datasets have their drawbacks. They have long been suffering from low-quality issues (e.g., low informativeness and redundancy). This explains why the massive synthetic data does not lead to better performance -- a scenario we would expect in the human-labeled data. To improve the quality of dataset synthesis, we propose a progressive zero-shot dataset generation framework, ProGen, which leverages the feedback from the task-specific model to guide the generation of new training data via in-context examples. Extensive experiments on five text classification datasets demonstrate the effectiveness of the proposed approach. We also show ProGen achieves on-par or superior performance with only 1\% synthetic dataset size compared to baseline methods without in-context feedback.
PDF Abstract



 SST
SST
 IMDb Movie Reviews
IMDb Movie Reviews
