Progressive Image Deraining Networks: A Better and Simpler Baseline
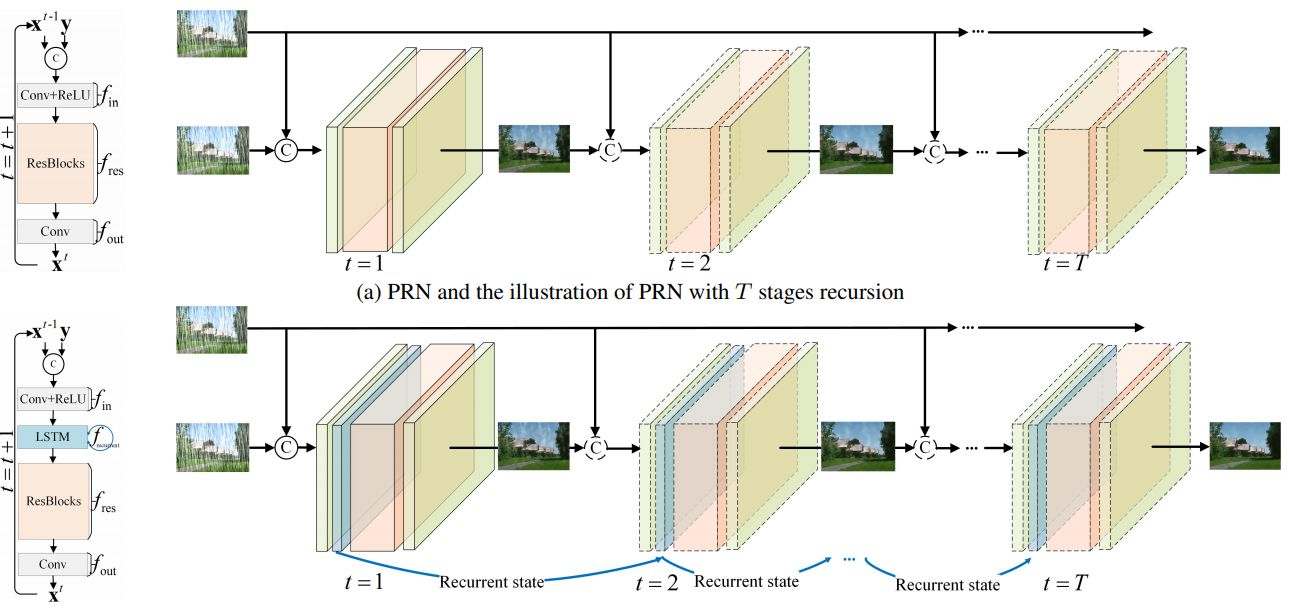
Along with the deraining performance improvement of deep networks, their structures and learning become more and more complicated and diverse, making it difficult to analyze the contribution of various network modules when developing new deraining networks. To handle this issue, this paper provides a better and simpler baseline deraining network by considering network architecture, input and output, and loss functions. Specifically, by repeatedly unfolding a shallow ResNet, progressive ResNet (PRN) is proposed to take advantage of recursive computation. A recurrent layer is further introduced to exploit the dependencies of deep features across stages, forming our progressive recurrent network (PReNet). Furthermore, intra-stage recursive computation of ResNet can be adopted in PRN and PReNet to notably reduce network parameters with graceful degradation in deraining performance. For network input and output, we take both stage-wise result and original rainy image as input to each ResNet and finally output the prediction of {residual image}. As for loss functions, single MSE or negative SSIM losses are sufficient to train PRN and PReNet. Experiments show that PRN and PReNet perform favorably on both synthetic and real rainy images. Considering its simplicity, efficiency and effectiveness, our models are expected to serve as a suitable baseline in future deraining research. The source codes are available at https://github.com/csdwren/PReNet.
PDF Abstract CVPR 2019 PDF CVPR 2019 Abstract




 Synthetic Rain Datasets
Synthetic Rain Datasets

