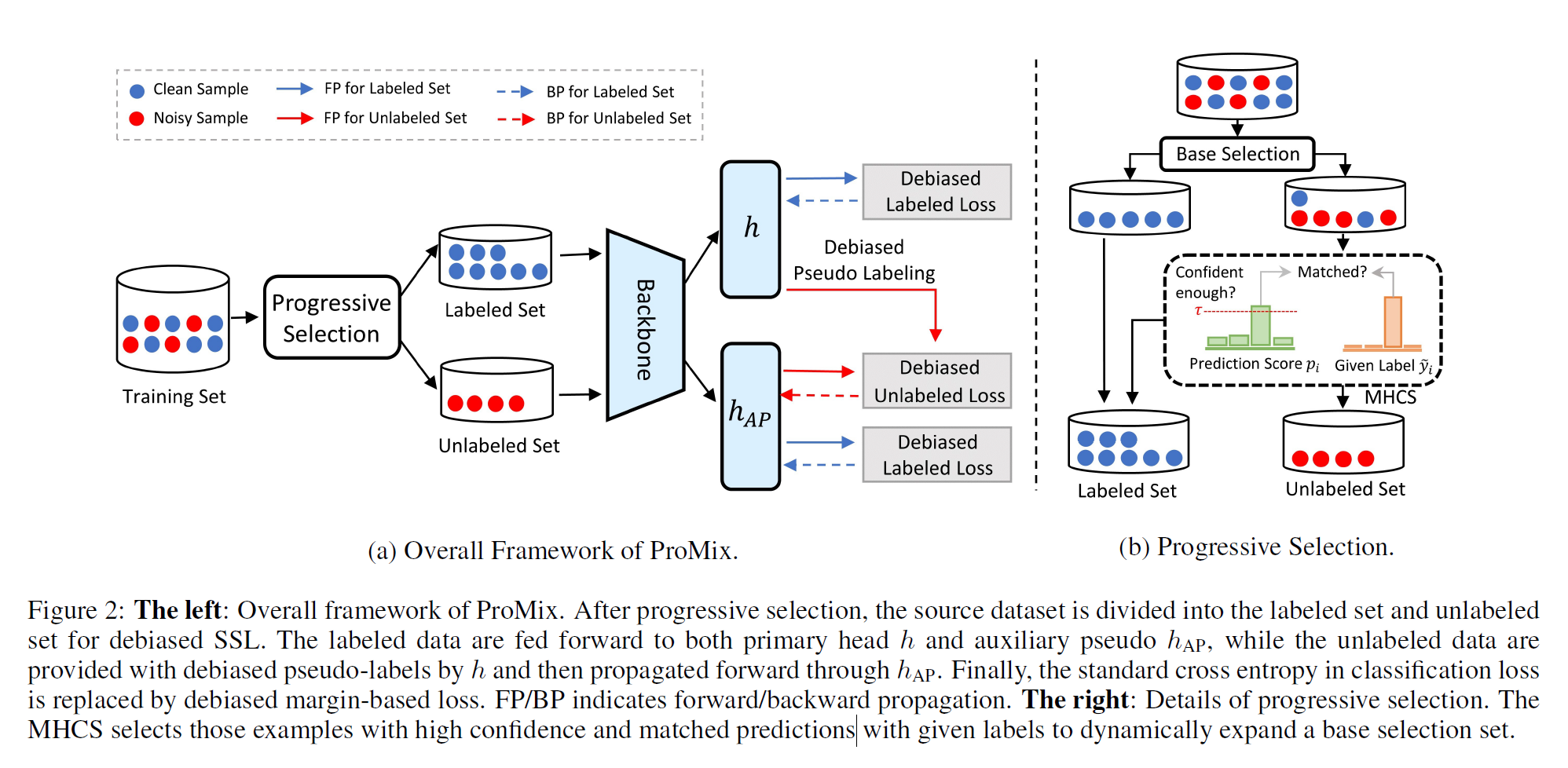
ProMix: Combating Label Noise via Maximizing Clean Sample Utility
Learning with Noisy Labels (LNL) has become an appealing topic, as imperfectly annotated data are relatively cheaper to obtain. Recent state-of-the-art approaches employ specific selection mechanisms to separate clean and noisy samples and then apply Semi-Supervised Learning (SSL) techniques for improved performance. However, the selection step mostly provides a medium-sized and decent-enough clean subset, which overlooks a rich set of clean samples. To fulfill this, we propose a novel LNL framework ProMix that attempts to maximize the utility of clean samples for boosted performance. Key to our method, we propose a matched high confidence selection technique that selects those examples with high confidence scores and matched predictions with given labels to dynamically expand a base clean sample set. To overcome the potential side effect of excessive clean set selection procedure, we further devise a novel SSL framework that is able to train balanced and unbiased classifiers on the separated clean and noisy samples. Extensive experiments demonstrate that ProMix significantly advances the current state-of-the-art results on multiple benchmarks with different types and levels of noise. It achieves an average improvement of 2.48\% on the CIFAR-N dataset. The code is available at https://github.com/Justherozen/ProMix
PDF Abstract

 CIFAR-10
CIFAR-10
 CIFAR-100
CIFAR-100
 Clothing1M
Clothing1M

