Prototypical Pseudo Label Denoising and Target Structure Learning for Domain Adaptive Semantic Segmentation
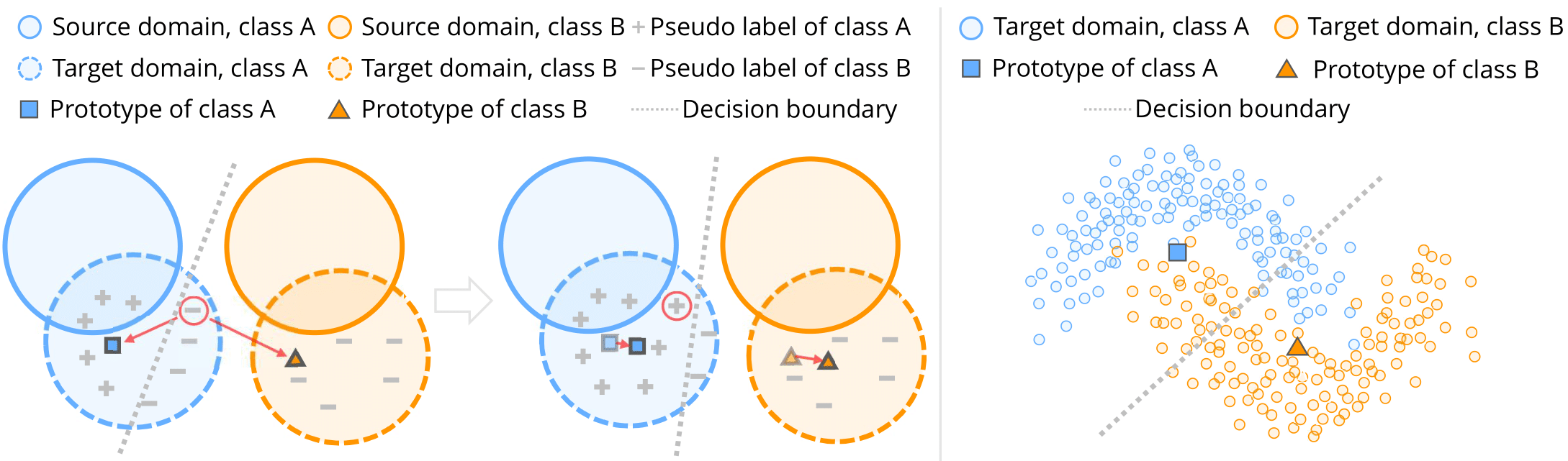
Self-training is a competitive approach in domain adaptive segmentation, which trains the network with the pseudo labels on the target domain. However inevitably, the pseudo labels are noisy and the target features are dispersed due to the discrepancy between source and target domains. In this paper, we rely on representative prototypes, the feature centroids of classes, to address the two issues for unsupervised domain adaptation. In particular, we take one step further and exploit the feature distances from prototypes that provide richer information than mere prototypes. Specifically, we use it to estimate the likelihood of pseudo labels to facilitate online correction in the course of training. Meanwhile, we align the prototypical assignments based on relative feature distances for two different views of the same target, producing a more compact target feature space. Moreover, we find that distilling the already learned knowledge to a self-supervised pretrained model further boosts the performance. Our method shows tremendous performance advantage over state-of-the-art methods. We will make the code publicly available.
PDF Abstract CVPR 2021 PDF CVPR 2021 Abstract





 Cityscapes
Cityscapes
 SYNTHIA
SYNTHIA
 GTA5
GTA5

