Pyramid Multi-view Stereo Net with Self-adaptive View Aggregation
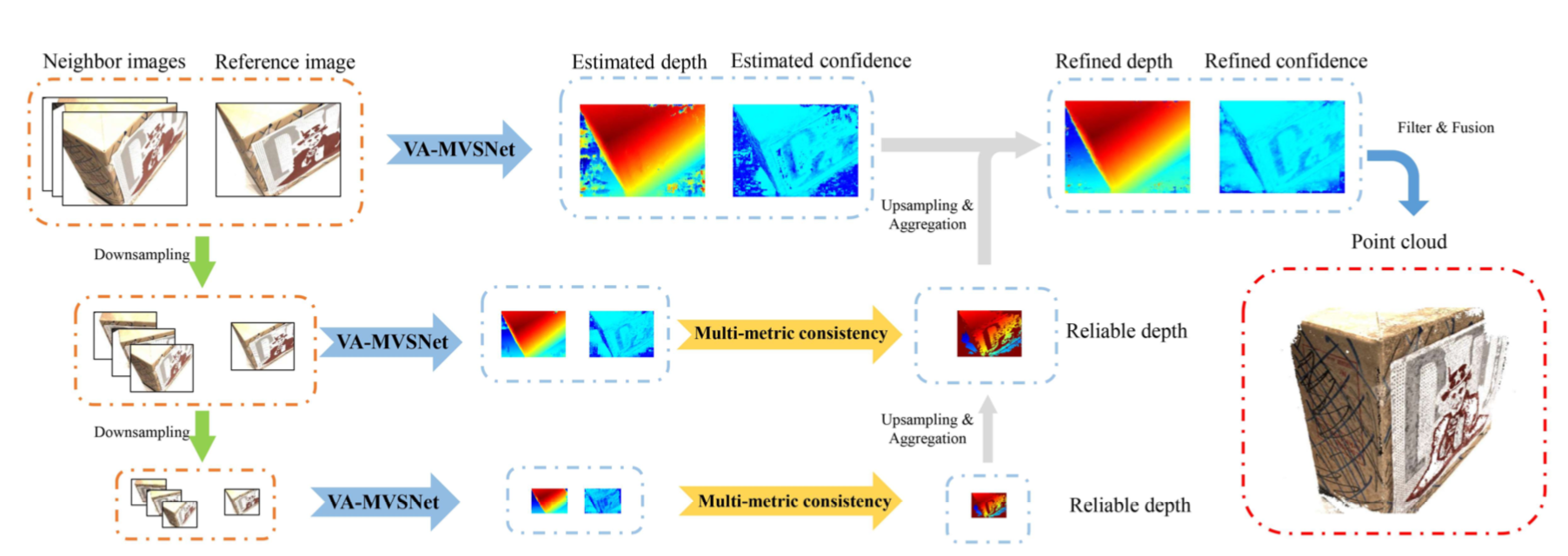
n this paper, we propose an effective and efficient pyramid multi-view stereo (MVS) net with self-adaptive view aggregation for accurate and complete dense point cloud reconstruction. Different from using mean square variance to generate cost volume in previous deep-learning based MVS methods, our \textbf{VA-MVSNet} incorporates the cost variances in different views with small extra memory consumption by introducing two novel self-adaptive view aggregations: pixel-wise view aggregation and voxel-wise view aggregation. To further boost the robustness and completeness of 3D point cloud reconstruction, we extend VA-MVSNet with pyramid multi-scale images input as \textbf{PVA-MVSNet}, where multi-metric constraints are leveraged to aggregate the reliable depth estimation at the coarser scale to fill in the mismatched regions at the finer scale. Experimental results show that our approach establishes a new state-of-the-art on the \textsl{\textbf{DTU}} dataset with significant improvements in the completeness and overall quality, and has strong generalization by achieving a comparable performance as the state-of-the-art methods on the \textsl{\textbf{Tanks and Temples}} benchmark. Our codebase is at \hyperlink{https://github.com/yhw-yhw/PVAMVSNet}{https://github.com/yhw-yhw/PVAMVSNet}
PDF Abstract ECCV 2020 PDF ECCV 2020 Abstract



