Query-Efficient Imitation Learning for End-to-End Autonomous Driving
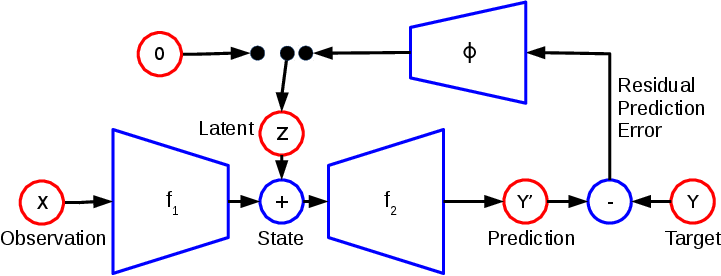
One way to approach end-to-end autonomous driving is to learn a policy function that maps from a sensory input, such as an image frame from a front-facing camera, to a driving action, by imitating an expert driver, or a reference policy. This can be done by supervised learning, where a policy function is tuned to minimize the difference between the predicted and ground-truth actions. A policy function trained in this way however is known to suffer from unexpected behaviours due to the mismatch between the states reachable by the reference policy and trained policy functions. More advanced algorithms for imitation learning, such as DAgger, addresses this issue by iteratively collecting training examples from both reference and trained policies. These algorithms often requires a large number of queries to a reference policy, which is undesirable as the reference policy is often expensive. In this paper, we propose an extension of the DAgger, called SafeDAgger, that is query-efficient and more suitable for end-to-end autonomous driving. We evaluate the proposed SafeDAgger in a car racing simulator and show that it indeed requires less queries to a reference policy. We observe a significant speed up in convergence, which we conjecture to be due to the effect of automated curriculum learning.
PDF Abstract


