RA-Depth: Resolution Adaptive Self-Supervised Monocular Depth Estimation
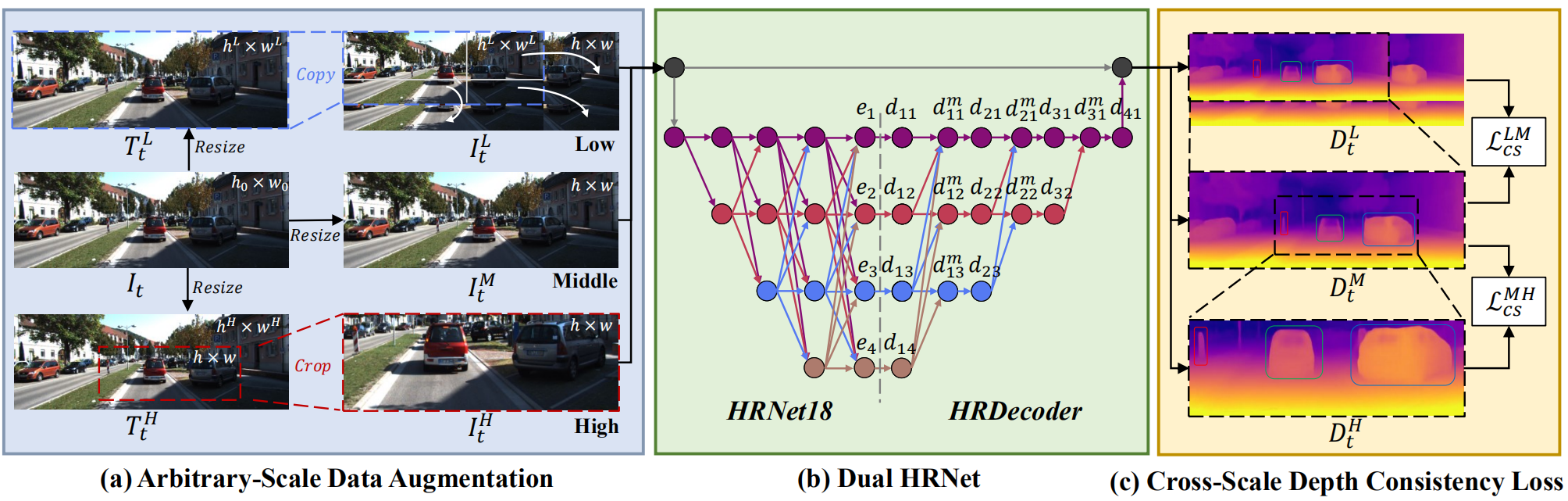
Existing self-supervised monocular depth estimation methods can get rid of expensive annotations and achieve promising results. However, these methods suffer from severe performance degradation when directly adopting a model trained on a fixed resolution to evaluate at other different resolutions. In this paper, we propose a resolution adaptive self-supervised monocular depth estimation method (RA-Depth) by learning the scale invariance of the scene depth. Specifically, we propose a simple yet efficient data augmentation method to generate images with arbitrary scales for the same scene. Then, we develop a dual high-resolution network that uses the multi-path encoder and decoder with dense interactions to aggregate multi-scale features for accurate depth inference. Finally, to explicitly learn the scale invariance of the scene depth, we formulate a cross-scale depth consistency loss on depth predictions with different scales. Extensive experiments on the KITTI, Make3D and NYU-V2 datasets demonstrate that RA-Depth not only achieves state-of-the-art performance, but also exhibits a good ability of resolution adaptation.
PDF Abstract



 NYUv2
NYUv2
 Make3D
Make3D
