
[Re] Learning Memory Guided Normality for Anomaly Detection
Scope of Reproducibility
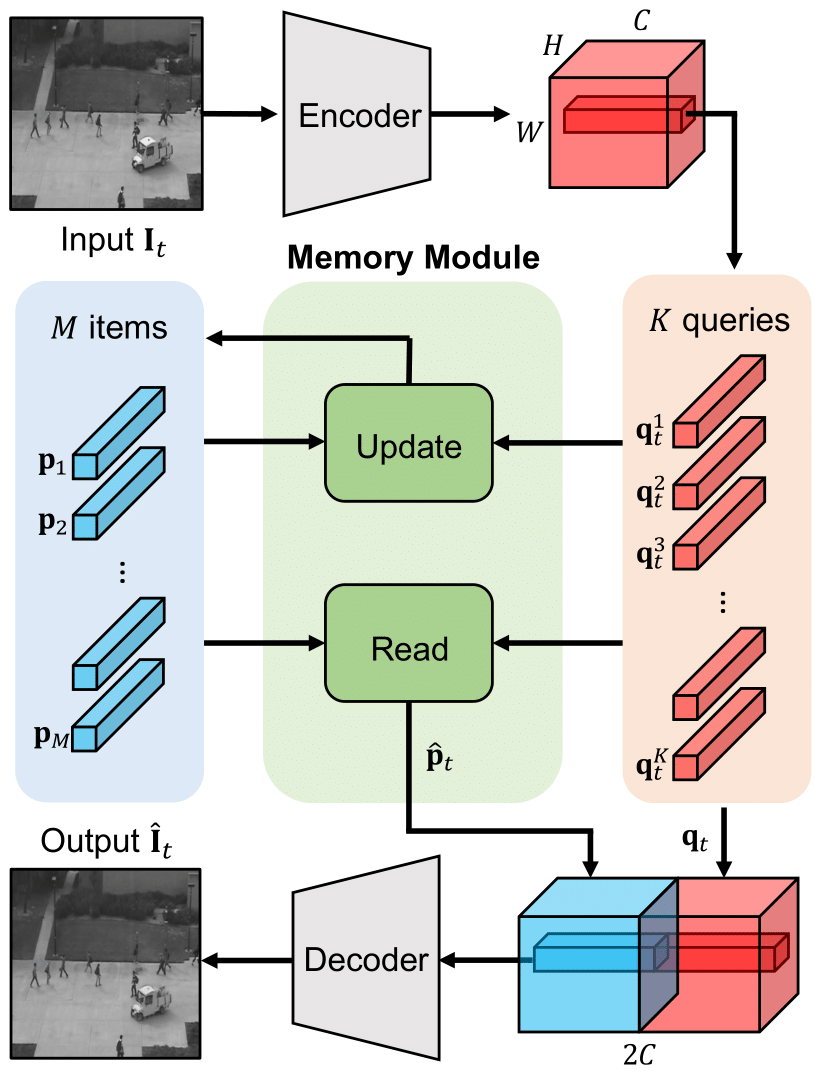
The authors have introduced a novel method for unsupervised anomaly detection that utilises a newly introduced “Memory Module” in their paper [1]. We validate the authorsʼ claim that this helps improve performance by helping the network learn prototypical patterns, and uses the learnt memory to reduce the representation capacity of Convolutional Neural Networks. Further, we validate the efficacy of two losses introduced by the authors, “Separateness Loss” and “Compactness Loss” presented to increase the discriminative power of the memory items and the deeply learned features. We test the efficacy with the help of t-SNE plots of the memory items.
Methodology
The authors provide a codebase available at https://github.com/cvlab-yonsei/MNAD with scripts for the Prediction task. We reused the available code to build scripts for the Reconstruction task and variants with and without memory. The completed codebase for all tasks available at https://github.com/alchemi5t/MNADrc.
Results
We obtain results that are within a 3% range of the reported results for all datasets other than on the ShanghaiTech dataset[2]. The anomalous run stuck out since the ”Non Memory” of the same run could score markedly better than the ”Memory” variant. This led us to investigate the behaviour of the memory module and found valuable insights which are presented in Section 5.
What was easy
• The authors provide codes to run the Prediction task with memory.
• The ideas presented in the paper were clear and easy to understand.
• The datasets were easily available, with the exception of the ShanghaiTech dataset[2].
What was difficult
• After training the model on the ShanghaiTech dataset[2], we found that the “Memory” variants of the model had issues as described in Sections 4 and 5. We investigated the behaviour of the memory module and introduced additional supervision to solve the problem.
• We required hyperparameter optimization to hit the reported scores.
• The paper also lacked information as to which parts of the pipeline were actually to be credited for the improvement in performance, as discussed in Section 5.
Communication with original authors
The codebase has scripts only for the Prediction task ”Memory” variant of the benchmarks. We reused portions of the codebase to create the other variants. We then validated our modifications with the authors. We also communicated the discrepancies we saw in parts of the results and the authors asked us to wait until they update their repository with the missing scripts.



