Reading StackOverflow Encourages Cheating: Adding Question Text Improves Extractive Code Generation
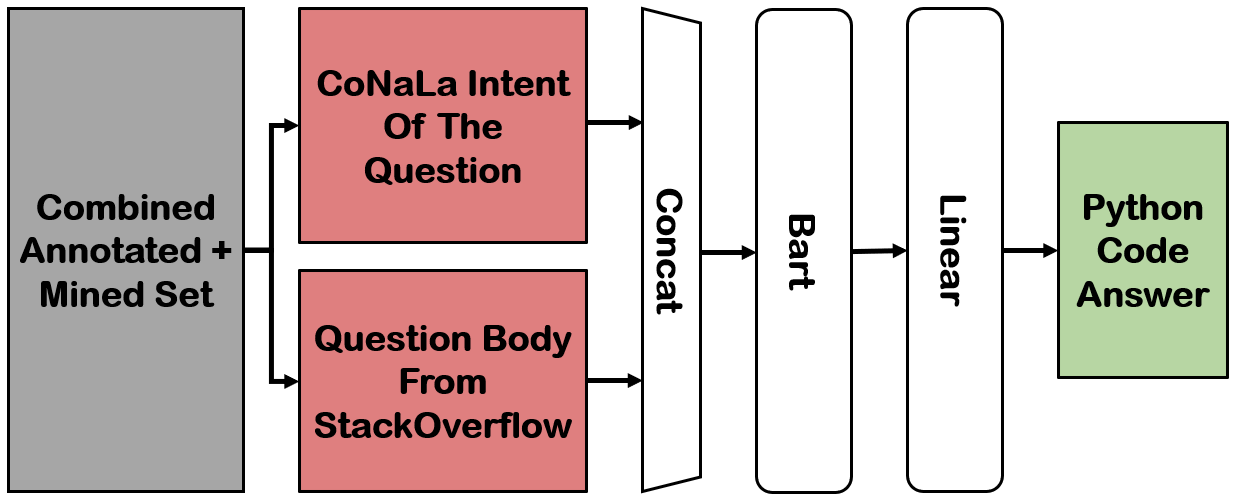
Answering a programming question using only its title is difficult as salient contextual information is omitted. Based on this observation, we present a corpus of over 40,000 StackOverflow question texts to be used in conjunction with their corresponding intents from the CoNaLa dataset (Yin et al., 2018). Using both the intent and question body, we use BART to establish a baseline BLEU score of 34.35 for this new task. We find further improvements of $2.8\%$ by combining the mined CoNaLa data with the labeled data to achieve a 35.32 BLEU score. We evaluate prior state-of-the-art CoNaLa models with this additional data and find that our proposed method of using the body and mined data beats the BLEU score of the prior state-of-the-art by $71.96\%$. Finally, we perform ablations to demonstrate that BART is an unsupervised multimodal learner and examine its extractive behavior. The code and data can be found https://github.com/gabeorlanski/stackoverflow-encourages-cheating.
PDF Abstract ACL (NLP4Prog) 2021 PDF ACL (NLP4Prog) 2021 AbstractCode
 Colab
Colab
Tasks

Datasets
 CoNaLa-Ext
CoNaLa-Ext
 JuICe
JuICe

| Task | Dataset | Model | Metric Name | Metric Value | Global Rank | Benchmark |
|---|---|---|---|---|---|---|
| Code Generation | CoNaLa | BART W/ Mined | BLEU | 30.55 | # 9 | |
| Code Generation | CoNaLa | BART Base | BLEU | 26.24 | # 13 | |
| Code Generation | CoNaLa-Ext | BART W/ Mined | BLEU | 35.32 | # 1 | |
| Code Generation | CoNaLa-Ext | BART Base | BLEU | 34.35 | # 2 |
