Real-time End-to-End Video Text Spotter with Contrastive Representation Learning
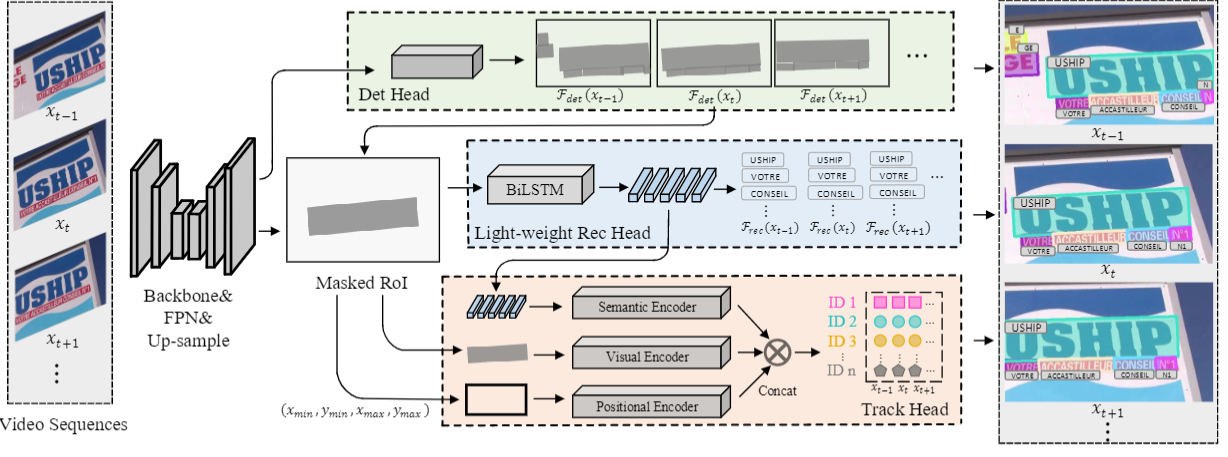
Video text spotting(VTS) is the task that requires simultaneously detecting, tracking and recognizing text in the video. Existing video text spotting methods typically develop sophisticated pipelines and multiple models, which is not friend for real-time applications. Here we propose a real-time end-to-end video text spotter with Contrastive Representation learning (CoText). Our contributions are three-fold: 1) CoText simultaneously address the three tasks (e.g., text detection, tracking, recognition) in a real-time end-to-end trainable framework. 2) With contrastive learning, CoText models long-range dependencies and learning temporal information across multiple frames. 3) A simple, lightweight architecture is designed for effective and accurate performance, including GPU-parallel detection post-processing, CTC-based recognition head with Masked RoI. Extensive experiments show the superiority of our method. Especially, CoText achieves an video text spotting IDF1 of 72.0% at 41.0 FPS on ICDAR2015video, with 10.5% and 32.0 FPS improvement the previous best method. The code can be found at github.com/weijiawu/CoText.
PDF Abstract



 ICDAR 2013
ICDAR 2013
 COCO-Text
COCO-Text
