RED: Reinforced Encoder-Decoder Networks for Action Anticipation
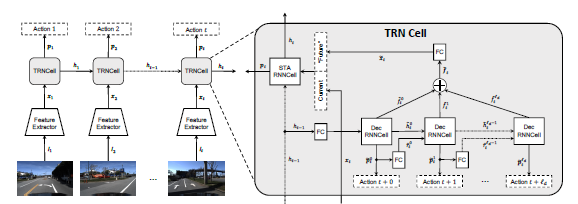
Action anticipation aims to detect an action before it happens. Many real world applications in robotics and surveillance are related to this predictive capability. Current methods address this problem by first anticipating visual representations of future frames and then categorizing the anticipated representations to actions. However, anticipation is based on a single past frame's representation, which ignores the history trend. Besides, it can only anticipate a fixed future time. We propose a Reinforced Encoder-Decoder (RED) network for action anticipation. RED takes multiple history representations as input and learns to anticipate a sequence of future representations. One salient aspect of RED is that a reinforcement module is adopted to provide sequence-level supervision; the reward function is designed to encourage the system to make correct predictions as early as possible. We test RED on TVSeries, THUMOS-14 and TV-Human-Interaction datasets for action anticipation and achieve state-of-the-art performance on all datasets.
PDF Abstract


