RedNet: Residual Encoder-Decoder Network for indoor RGB-D Semantic Segmentation
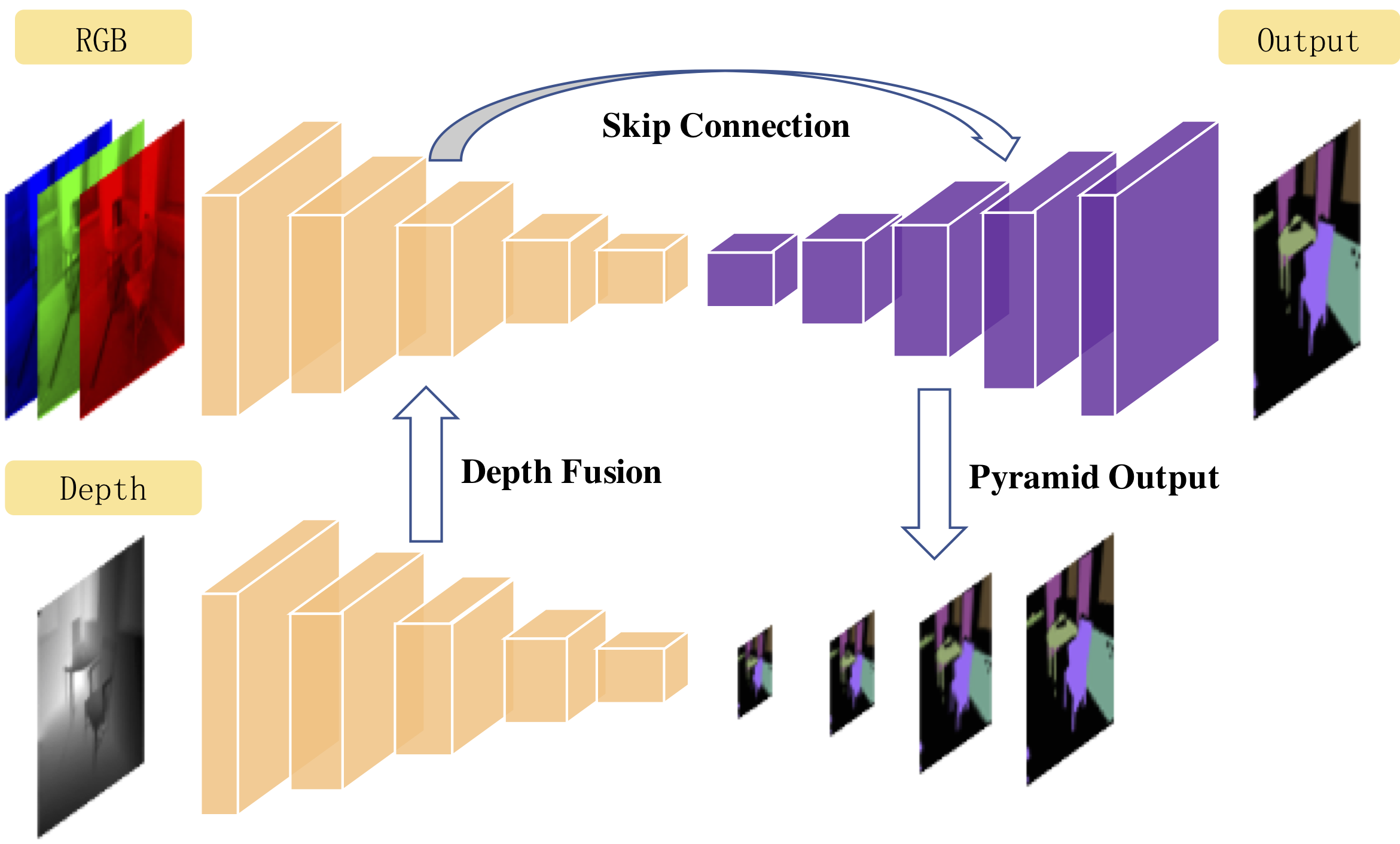
Indoor semantic segmentation has always been a difficult task in computer vision. In this paper, we propose an RGB-D residual encoder-decoder architecture, named RedNet, for indoor RGB-D semantic segmentation. In RedNet, the residual module is applied to both the encoder and decoder as the basic building block, and the skip-connection is used to bypass the spatial feature between the encoder and decoder. In order to incorporate the depth information of the scene, a fusion structure is constructed, which makes inference on RGB image and depth image separately, and fuses their features over several layers. In order to efficiently optimize the network's parameters, we propose a `pyramid supervision' training scheme, which applies supervised learning over different layers in the decoder, to cope with the problem of gradients vanishing. Experiment results show that the proposed RedNet(ResNet-50) achieves a state-of-the-art mIoU accuracy of 47.8% on the SUN RGB-D benchmark dataset.
PDF AbstractCode




 NYUv2
NYUv2
 SUN RGB-D
SUN RGB-D
Results from the Paper
 Ranked #26 on
Semantic Segmentation
on SUN-RGBD
(using extra training data)
Ranked #26 on
Semantic Segmentation
on SUN-RGBD
(using extra training data)
