Referring Expression Object Segmentation with Caption-Aware Consistency
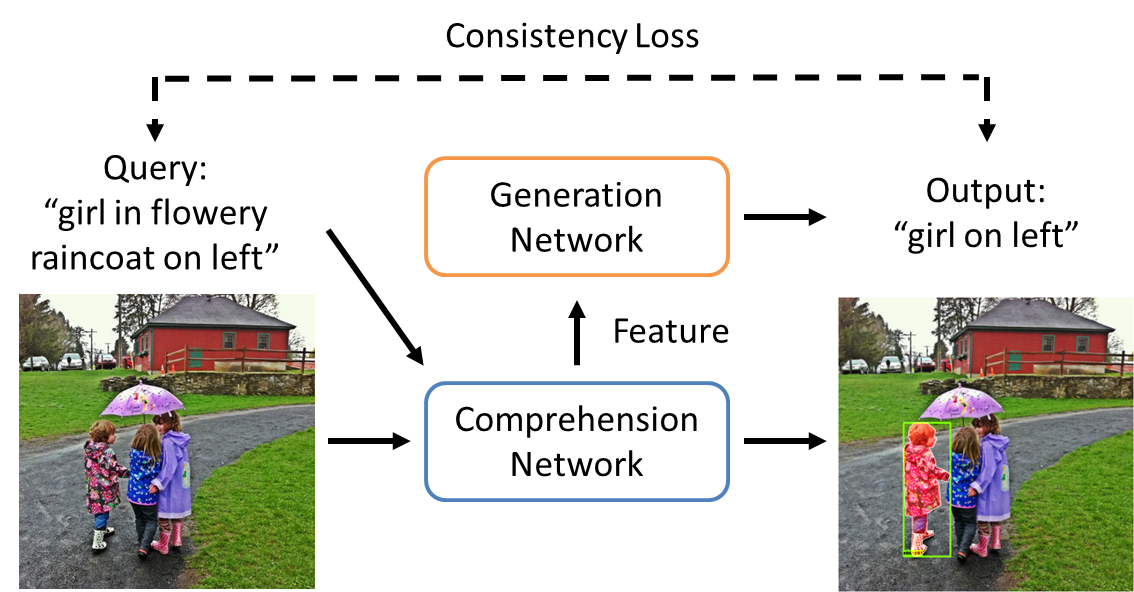
Referring expressions are natural language descriptions that identify a particular object within a scene and are widely used in our daily conversations. In this work, we focus on segmenting the object in an image specified by a referring expression. To this end, we propose an end-to-end trainable comprehension network that consists of the language and visual encoders to extract feature representations from both domains. We introduce the spatial-aware dynamic filters to transfer knowledge from text to image, and effectively capture the spatial information of the specified object. To better communicate between the language and visual modules, we employ a caption generation network that takes features shared across both domains as input, and improves both representations via a consistency that enforces the generated sentence to be similar to the given referring expression. We evaluate the proposed framework on two referring expression datasets and show that our method performs favorably against the state-of-the-art algorithms.
PDF Abstract



 MS COCO
MS COCO
 RefCOCO
RefCOCO

