Refign: Align and Refine for Adaptation of Semantic Segmentation to Adverse Conditions
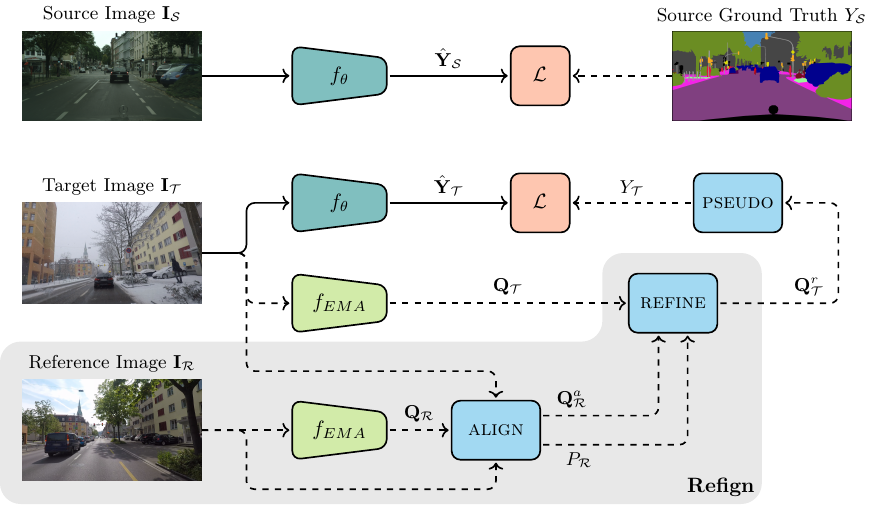
Due to the scarcity of dense pixel-level semantic annotations for images recorded in adverse visual conditions, there has been a keen interest in unsupervised domain adaptation (UDA) for the semantic segmentation of such images. UDA adapts models trained on normal conditions to the target adverse-condition domains. Meanwhile, multiple datasets with driving scenes provide corresponding images of the same scenes across multiple conditions, which can serve as a form of weak supervision for domain adaptation. We propose Refign, a generic extension to self-training-based UDA methods which leverages these cross-domain correspondences. Refign consists of two steps: (1) aligning the normal-condition image to the corresponding adverse-condition image using an uncertainty-aware dense matching network, and (2) refining the adverse prediction with the normal prediction using an adaptive label correction mechanism. We design custom modules to streamline both steps and set the new state of the art for domain-adaptive semantic segmentation on several adverse-condition benchmarks, including ACDC and Dark Zurich. The approach introduces no extra training parameters, minimal computational overhead -- during training only -- and can be used as a drop-in extension to improve any given self-training-based UDA method. Code is available at https://github.com/brdav/refign.
PDF AbstractCode




 Cityscapes
Cityscapes
 MegaDepth
MegaDepth
 Dark Zurich
Dark Zurich
 Oxford RobotCar Dataset
Oxford RobotCar Dataset
 Nighttime Driving
Nighttime Driving

| Task | Dataset | Model | Metric Name | Metric Value | Global Rank | Benchmark |
|---|---|---|---|---|---|---|
| Domain Adaptation | Cityscapes to ACDC | Refign (DAFormer) | mIoU | 65.5 | # 6 | |
| Domain Adaptation | Cityscapes to ACDC | Refign (HRDA) | mIoU | 72.1 | # 3 | |
| Semantic Segmentation | Dark Zurich | Refign (HRDA) | mIoU | 63.9 | # 1 | |
| Semantic Segmentation | Dark Zurich | Refign (DAFormer) | mIoU | 56.2 | # 4 | |
| Semantic Segmentation | Nighttime Driving | Refign (DAFormer) | mIoU | 56.8 | # 4 | |
| Semantic Segmentation | Nighttime Driving | Refign (HRDA) | mIoU | 58.0 | # 3 |
