Regularizing Deep Networks with Semantic Data Augmentation
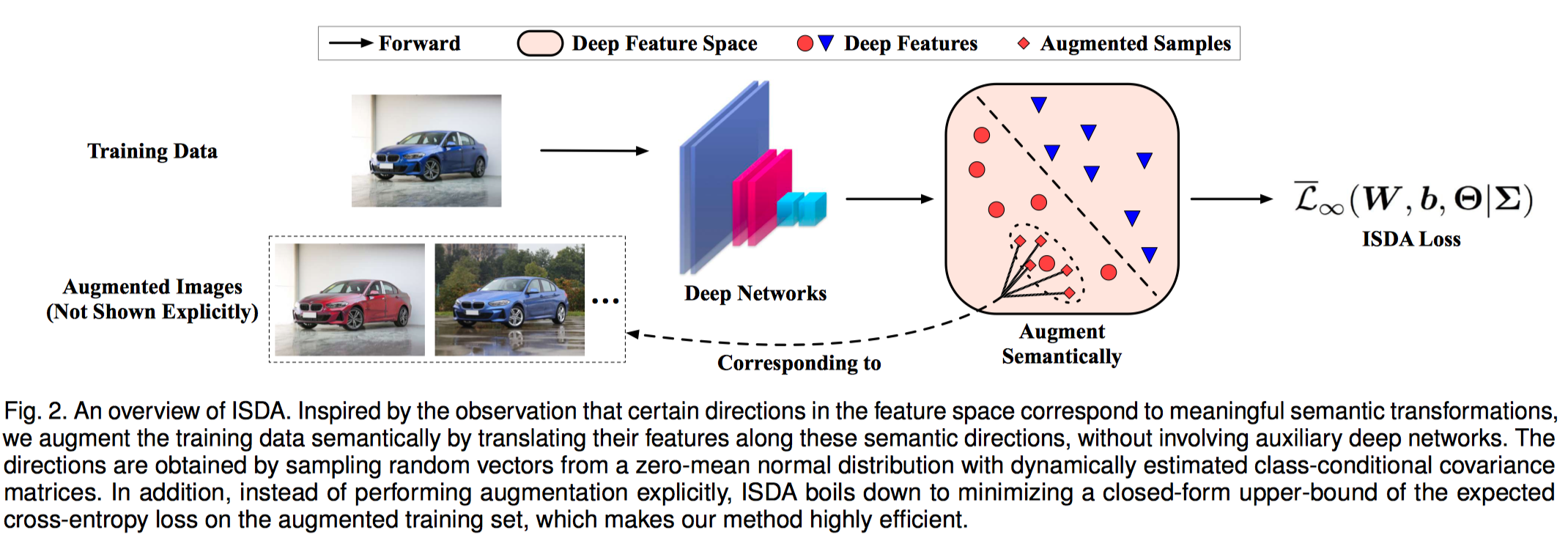
Data augmentation is widely known as a simple yet surprisingly effective technique for regularizing deep networks. Conventional data augmentation schemes, e.g., flipping, translation or rotation, are low-level, data-independent and class-agnostic operations, leading to limited diversity for augmented samples. To this end, we propose a novel semantic data augmentation algorithm to complement traditional approaches. The proposed method is inspired by the intriguing property that deep networks are effective in learning linearized features, i.e., certain directions in the deep feature space correspond to meaningful semantic transformations, e.g., changing the background or view angle of an object. Based on this observation, translating training samples along many such directions in the feature space can effectively augment the dataset for more diversity. To implement this idea, we first introduce a sampling based method to obtain semantically meaningful directions efficiently. Then, an upper bound of the expected cross-entropy (CE) loss on the augmented training set is derived by assuming the number of augmented samples goes to infinity, yielding a highly efficient algorithm. In fact, we show that the proposed implicit semantic data augmentation (ISDA) algorithm amounts to minimizing a novel robust CE loss, which adds minimal extra computational cost to a normal training procedure. In addition to supervised learning, ISDA can be applied to semi-supervised learning tasks under the consistency regularization framework, where ISDA amounts to minimizing the upper bound of the expected KL-divergence between the augmented features and the original features. Although being simple, ISDA consistently improves the generalization performance of popular deep models (e.g., ResNets and DenseNets) on a variety of datasets, i.e., CIFAR-10, CIFAR-100, SVHN, ImageNet, and Cityscapes.
PDF Abstract

 CIFAR-10
CIFAR-10
 ImageNet
ImageNet
 CIFAR-100
CIFAR-100
 Cityscapes
Cityscapes
