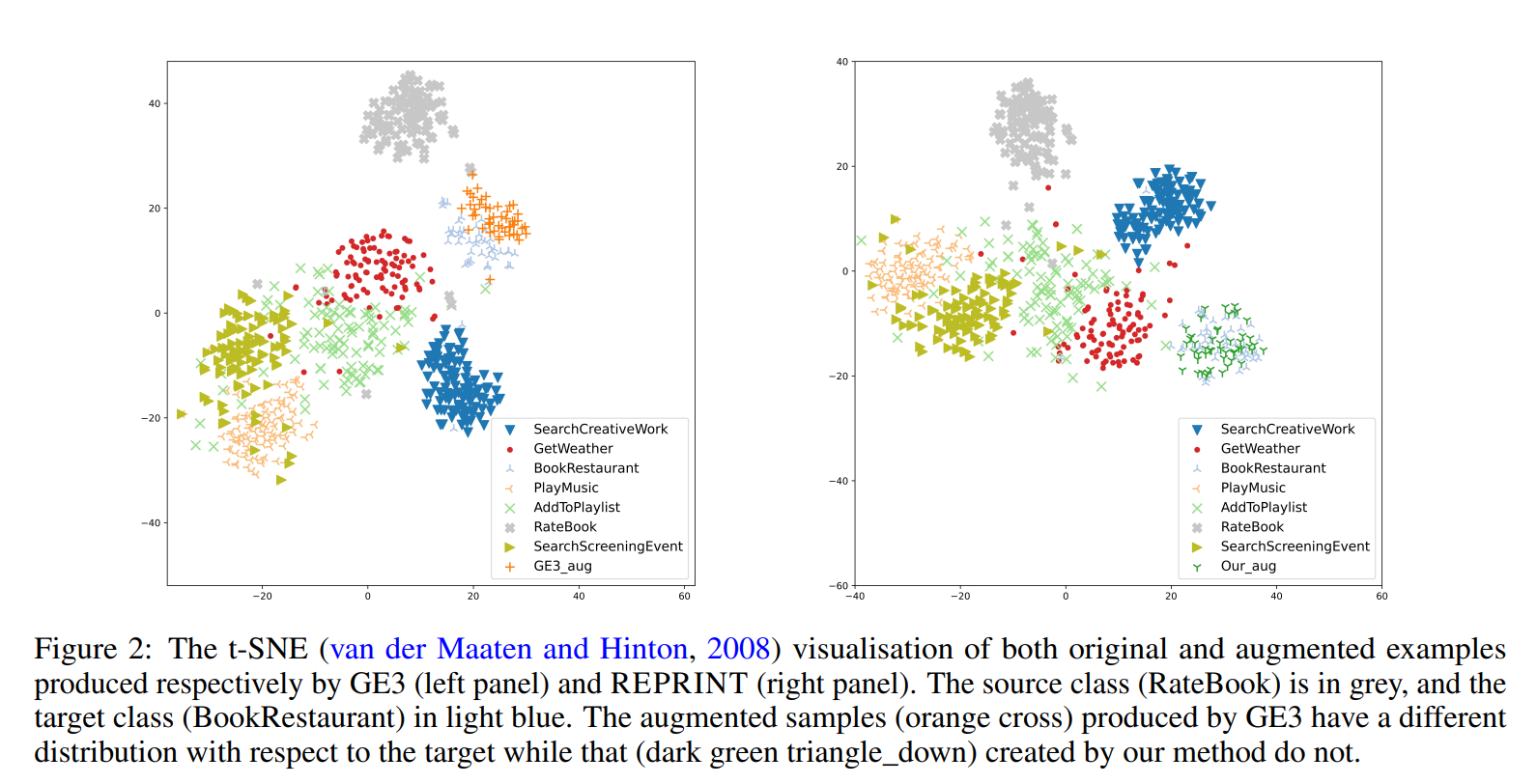
Reprint: a randomized extrapolation based on principal components for data augmentation
Data scarcity and data imbalance have attracted a lot of attention in many fields. Data augmentation, explored as an effective approach to tackle them, can improve the robustness and efficiency of classification models by generating new samples. This paper presents REPRINT, a simple and effective hidden-space data augmentation method for imbalanced data classification. Given hidden-space representations of samples in each class, REPRINT extrapolates, in a randomized fashion, augmented examples for target class by using subspaces spanned by principal components to summarize distribution structure of both source and target class. Consequently, the examples generated would diversify the target while maintaining the original geometry of target distribution. Besides, this method involves a label refinement component which allows to synthesize new soft labels for augmented examples. Compared with different NLP data augmentation approaches under a range of data imbalanced scenarios on four text classification benchmark, REPRINT shows prominent improvements. Moreover, through comprehensive ablation studies, we show that label refinement is better than label-preserving for augmented examples, and that our method suggests stable and consistent improvements in terms of suitable choices of principal components. Moreover, REPRINT is appealing for its easy-to-use since it contains only one hyperparameter determining the dimension of subspace and requires low computational resource.
PDF Abstract


 AG News
AG News
 SNIPS
SNIPS
