Rethinking Semantic Segmentation: A Prototype View
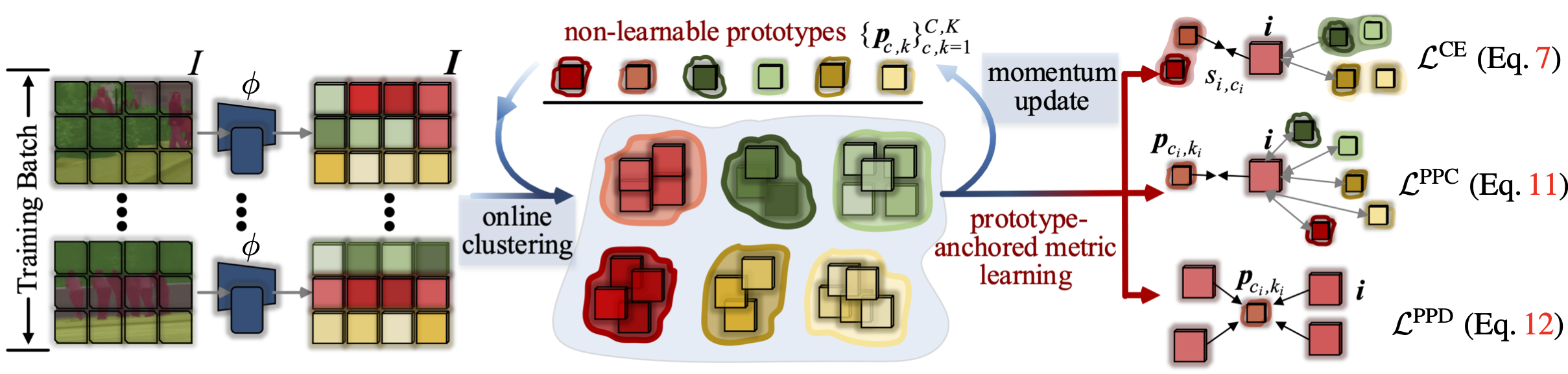
Prevalent semantic segmentation solutions, despite their different network designs (FCN based or attention based) and mask decoding strategies (parametric softmax based or pixel-query based), can be placed in one category, by considering the softmax weights or query vectors as learnable class prototypes. In light of this prototype view, this study uncovers several limitations of such parametric segmentation regime, and proposes a nonparametric alternative based on non-learnable prototypes. Instead of prior methods learning a single weight/query vector for each class in a fully parametric manner, our model represents each class as a set of non-learnable prototypes, relying solely on the mean features of several training pixels within that class. The dense prediction is thus achieved by nonparametric nearest prototype retrieving. This allows our model to directly shape the pixel embedding space, by optimizing the arrangement between embedded pixels and anchored prototypes. It is able to handle arbitrary number of classes with a constant amount of learnable parameters. We empirically show that, with FCN based and attention based segmentation models (i.e., HRNet, Swin, SegFormer) and backbones (i.e., ResNet, HRNet, Swin, MiT), our nonparametric framework yields compelling results over several datasets (i.e., ADE20K, Cityscapes, COCO-Stuff), and performs well in the large-vocabulary situation. We expect this work will provoke a rethink of the current de facto semantic segmentation model design.
PDF Abstract CVPR 2022 PDF CVPR 2022 Abstract


 Cityscapes
Cityscapes
 ADE20K
ADE20K
