Rethinking Training from Scratch for Object Detection
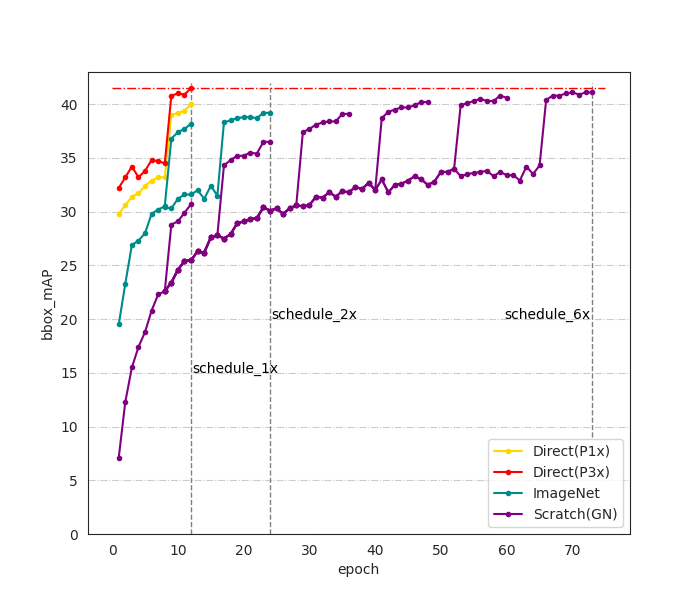
The ImageNet pre-training initialization is the de-facto standard for object detection. He et al. found it is possible to train detector from scratch(random initialization) while needing a longer training schedule with proper normalization technique. In this paper, we explore to directly pre-training on target dataset for object detection. Under this situation, we discover that the widely adopted large resizing strategy e.g. resize image to (1333, 800) is important for fine-tuning but it's not necessary for pre-training. Specifically, we propose a new training pipeline for object detection that follows `pre-training and fine-tuning', utilizing low resolution images within target dataset to pre-training detector then load it to fine-tuning with high resolution images. With this strategy, we can use batch normalization(BN) with large bath size during pre-training, it's also memory efficient that we can apply it on machine with very limited GPU memory(11G). We call it direct detection pre-training, and also use direct pre-training for short. Experiment results show that direct pre-training accelerates the pre-training phase by more than 11x on COCO dataset while with even +1.8mAP compared to ImageNet pre-training. Besides, we found direct pre-training is also applicable to transformer based backbones e.g. Swin Transformer. Code will be available.
PDF Abstract


 ImageNet
ImageNet
 MS COCO
MS COCO
