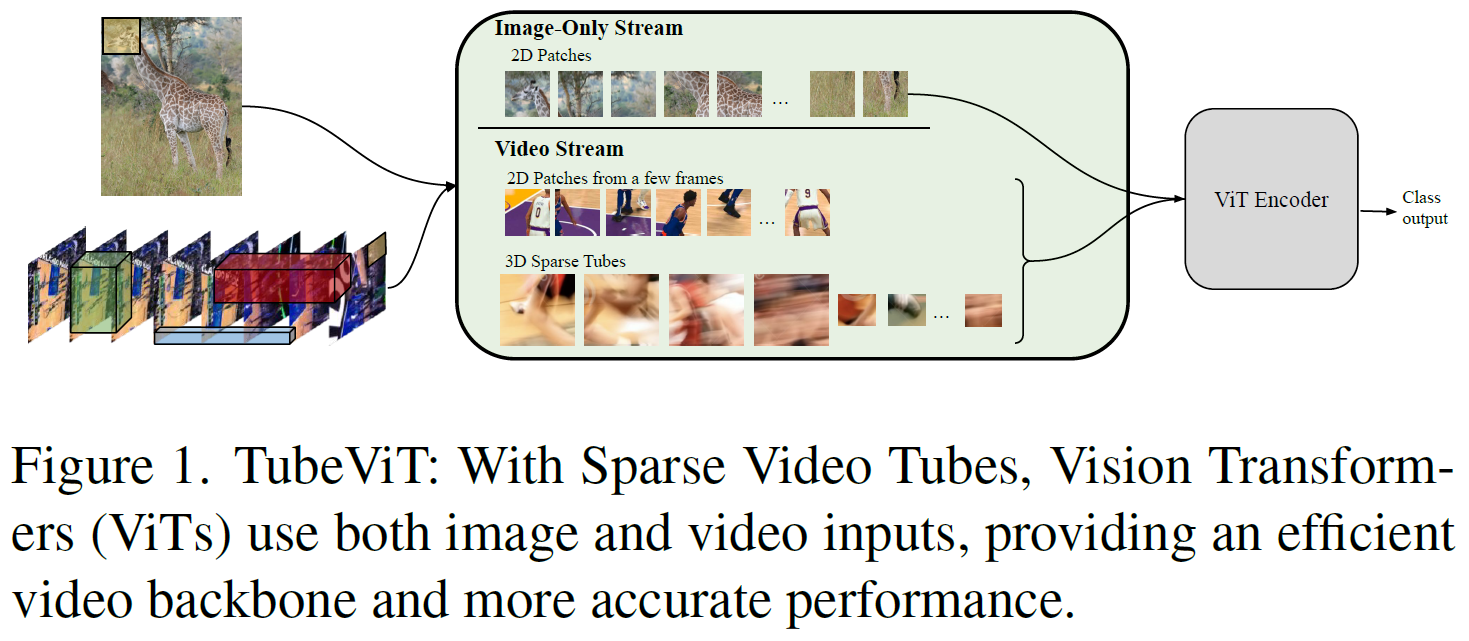
Rethinking Video ViTs: Sparse Video Tubes for Joint Image and Video Learning
We present a simple approach which can turn a ViT encoder into an efficient video model, which can seamlessly work with both image and video inputs. By sparsely sampling the inputs, the model is able to do training and inference from both inputs. The model is easily scalable and can be adapted to large-scale pre-trained ViTs without requiring full finetuning. The model achieves SOTA results and the code will be open-sourced.
PDF Abstract CVPR 2023 PDF CVPR 2023 AbstractCode




 Kinetics
Kinetics
 Kinetics 400
Kinetics 400
 Charades
Charades
 Something-Something V2
Something-Something V2
 Kinetics-600
Kinetics-600
 Kinetics-700
Kinetics-700
Results from the Paper
 Ranked #2 on
Action Classification
on Kinetics-600
(using extra training data)
Ranked #2 on
Action Classification
on Kinetics-600
(using extra training data)
