Retinal OCT disease classification with variational autoencoder regularization
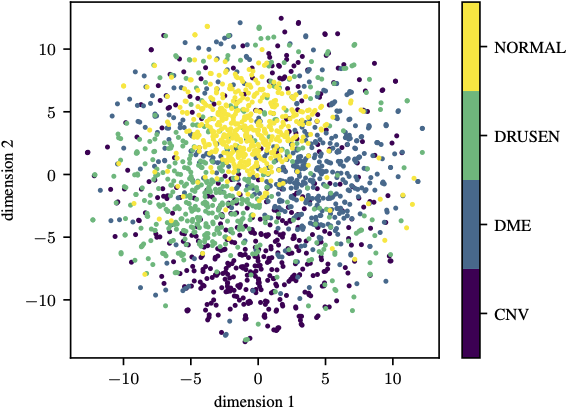
According to the World Health Organization, 285 million people worldwide live with visual impairment. The most commonly used imaging technique for diagnosis in ophthalmology is optical coherence tomography (OCT). However, analysis of retinal OCT requires trained ophthalmologists and time, making a comprehensive early diagnosis unlikely. A recent study established a diagnostic tool based on convolutional neural networks (CNN), which was trained on a large database of retinal OCT images. The performance of the tool in classifying retinal conditions was on par to that of trained medical experts. However, the training of these networks is based on an enormous amount of labeled data, which is expensive and difficult to obtain. Therefore, this paper describes a method based on variational autoencoder regularization that improves classification performance when using a limited amount of labeled data. This work uses a two-path CNN model combining a classification network with an autoencoder (AE) for regularization. The key idea behind this is to prevent overfitting when using a limited training dataset size with small number of patients. Results show superior classification performance compared to a pre-trained and fully fine-tuned baseline ResNet-34. Clustering of the latent space in relation to the disease class is distinct. Neural networks for disease classification on OCTs can benefit from regularization using variational autoencoders when trained with limited amount of patient data. Especially in the medical imaging domain, data annotated by experts is expensive to obtain.
PDF Abstract




