Retrieve, Read, Rerank: Towards End-to-End Multi-Document Reading Comprehension
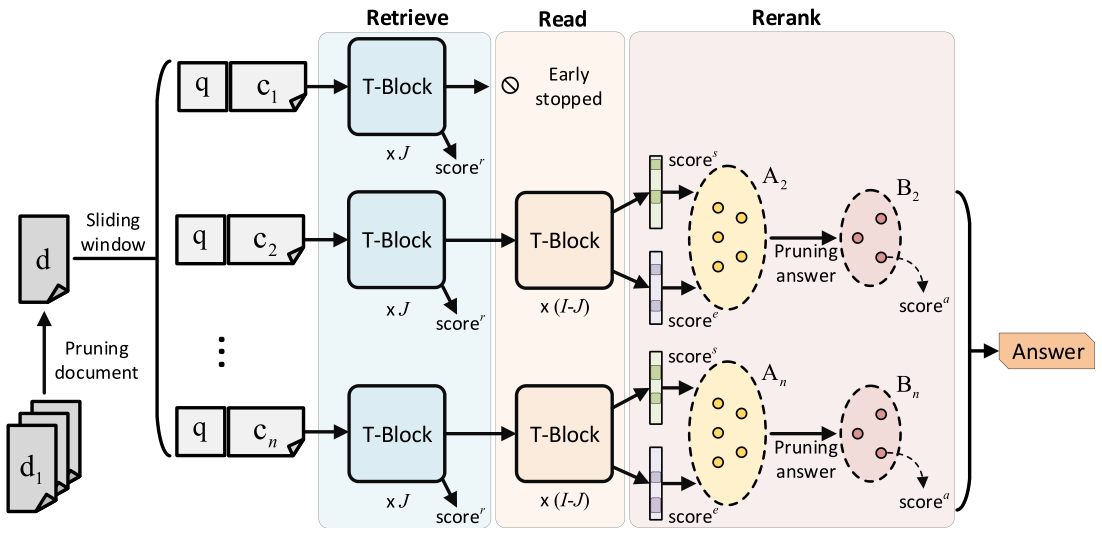
This paper considers the reading comprehension task in which multiple documents are given as input. Prior work has shown that a pipeline of retriever, reader, and reranker can improve the overall performance. However, the pipeline system is inefficient since the input is re-encoded within each module, and is unable to leverage upstream components to help downstream training. In this work, we present RE$^3$QA, a unified question answering model that combines context retrieving, reading comprehension, and answer reranking to predict the final answer. Unlike previous pipelined approaches, RE$^3$QA shares contextualized text representation across different components, and is carefully designed to use high-quality upstream outputs (e.g., retrieved context or candidate answers) for directly supervising downstream modules (e.g., the reader or the reranker). As a result, the whole network can be trained end-to-end to avoid the context inconsistency problem. Experiments show that our model outperforms the pipelined baseline and achieves state-of-the-art results on two versions of TriviaQA and two variants of SQuAD.
PDF Abstract ACL 2019 PDF ACL 2019 Abstract



 SQuAD
SQuAD
 TriviaQA
TriviaQA
