Revisiting k-NN for Fine-tuning Pre-trained Language Models
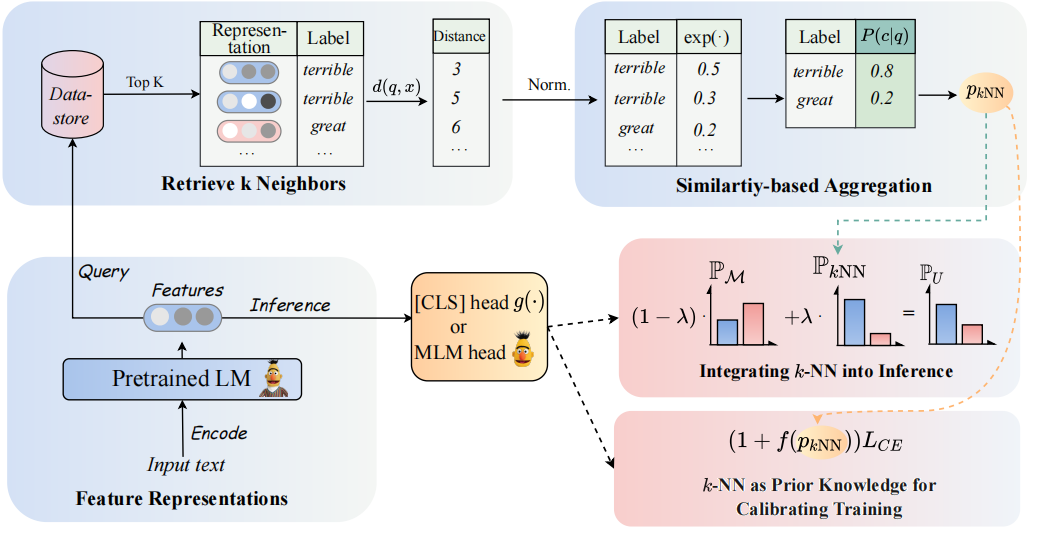
Pre-trained Language Models (PLMs), as parametric-based eager learners, have become the de-facto choice for current paradigms of Natural Language Processing (NLP). In contrast, k-Nearest-Neighbor (kNN) classifiers, as the lazy learning paradigm, tend to mitigate over-fitting and isolated noise. In this paper, we revisit kNN classifiers for augmenting the PLMs-based classifiers. From the methodological level, we propose to adopt kNN with textual representations of PLMs in two steps: (1) Utilize kNN as prior knowledge to calibrate the training process. (2) Linearly interpolate the probability distribution predicted by kNN with that of the PLMs' classifier. At the heart of our approach is the implementation of kNN-calibrated training, which treats predicted results as indicators for easy versus hard examples during the training process. From the perspective of the diversity of application scenarios, we conduct extensive experiments on fine-tuning, prompt-tuning paradigms and zero-shot, few-shot and fully-supervised settings, respectively, across eight diverse end-tasks. We hope our exploration will encourage the community to revisit the power of classical methods for efficient NLP. Code and datasets are available in https://github.com/zjunlp/Revisit-KNN.
PDF Abstract
 GLUE
GLUE
 SST
SST
 MultiNLI
MultiNLI
 BoolQ
BoolQ
