Revisiting Representation Learning for Singing Voice Separation with Sinkhorn Distances
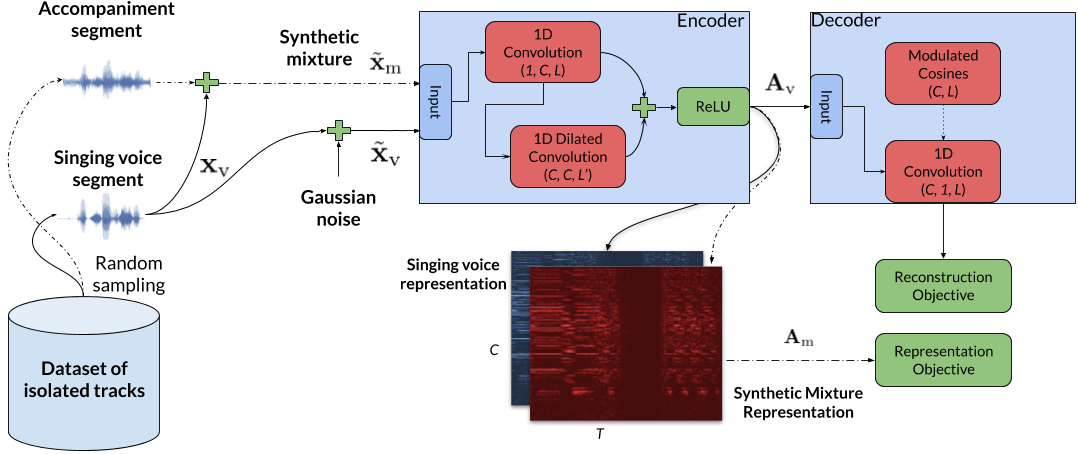
In this work we present a method for unsupervised learning of audio representations, focused on the task of singing voice separation. We build upon a previously proposed method for learning representations of time-domain music signals with a re-parameterized denoising autoencoder, extending it by using the family of Sinkhorn distances with entropic regularization. We evaluate our method on the freely available MUSDB18 dataset of professionally produced music recordings, and our results show that Sinkhorn distances with small strength of entropic regularization are marginally improving the performance of informed singing voice separation. By increasing the strength of the entropic regularization, the learned representations of the mixture signal consists of almost perfectly additive and distinctly structured sources.
PDF Abstract
 MUSDB18
MUSDB18
