Reward Delay Attacks on Deep Reinforcement Learning
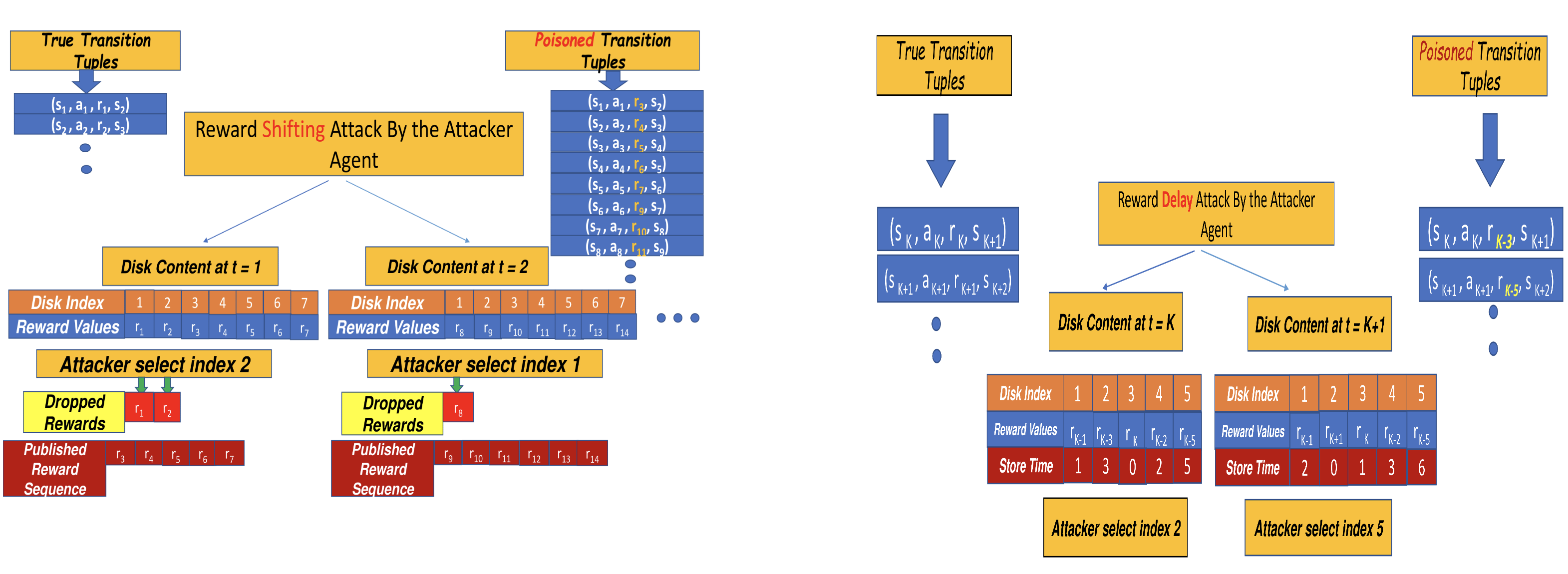
Most reinforcement learning algorithms implicitly assume strong synchrony. We present novel attacks targeting Q-learning that exploit a vulnerability entailed by this assumption by delaying the reward signal for a limited time period. We consider two types of attack goals: targeted attacks, which aim to cause a target policy to be learned, and untargeted attacks, which simply aim to induce a policy with a low reward. We evaluate the efficacy of the proposed attacks through a series of experiments. Our first observation is that reward-delay attacks are extremely effective when the goal is simply to minimize reward. Indeed, we find that even naive baseline reward-delay attacks are also highly successful in minimizing the reward. Targeted attacks, on the other hand, are more challenging, although we nevertheless demonstrate that the proposed approaches remain highly effective at achieving the attacker's targets. In addition, we introduce a second threat model that captures a minimal mitigation that ensures that rewards cannot be used out of sequence. We find that this mitigation remains insufficient to ensure robustness to attacks that delay, but preserve the order, of rewards.
PDF Abstract


 OpenAI Gym
OpenAI Gym
 Arcade Learning Environment
Arcade Learning Environment
