Rigging the Lottery: Making All Tickets Winners
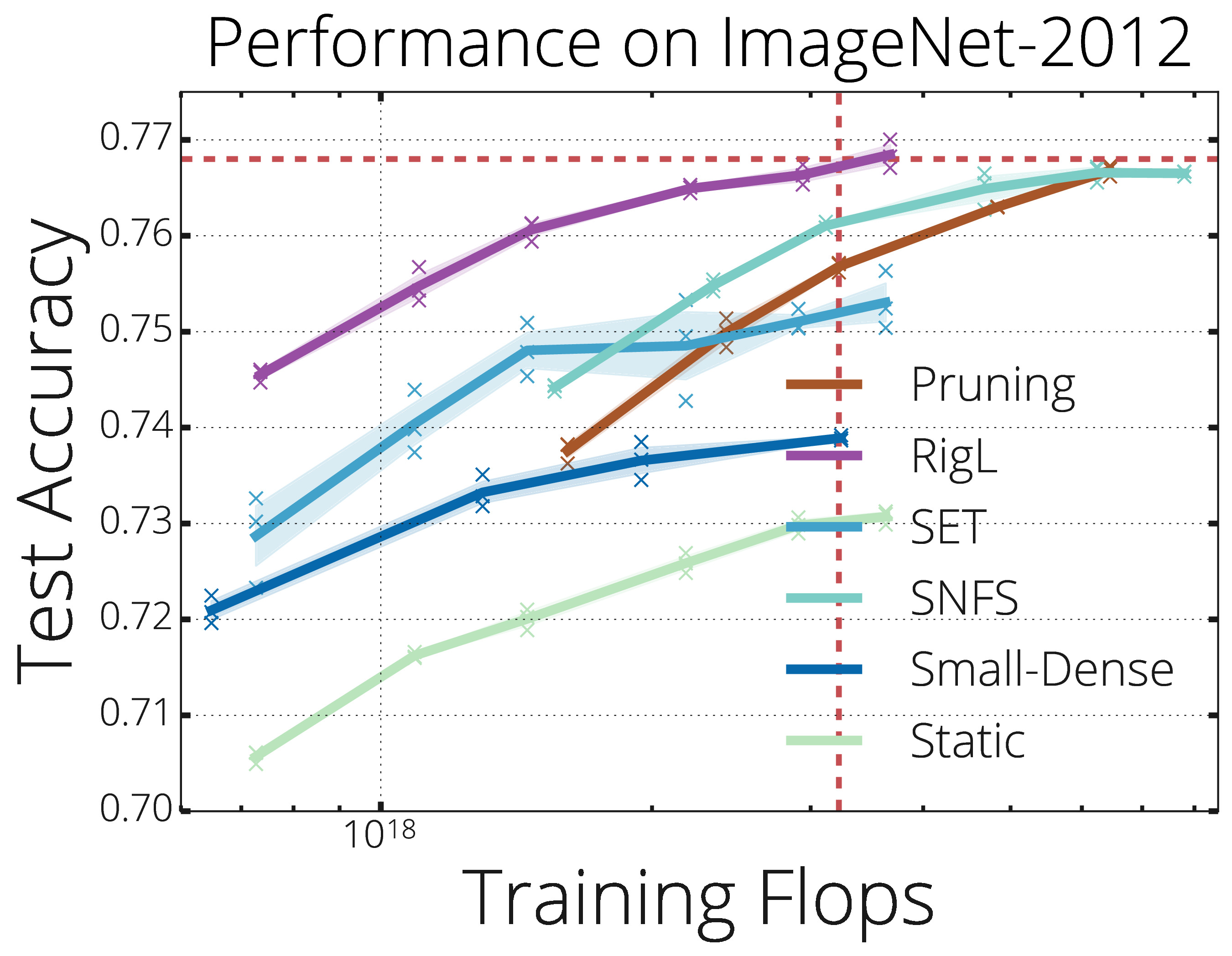
Many applications require sparse neural networks due to space or inference time restrictions. There is a large body of work on training dense networks to yield sparse networks for inference, but this limits the size of the largest trainable sparse model to that of the largest trainable dense model. In this paper we introduce a method to train sparse neural networks with a fixed parameter count and a fixed computational cost throughout training, without sacrificing accuracy relative to existing dense-to-sparse training methods. Our method updates the topology of the sparse network during training by using parameter magnitudes and infrequent gradient calculations. We show that this approach requires fewer floating-point operations (FLOPs) to achieve a given level of accuracy compared to prior techniques. We demonstrate state-of-the-art sparse training results on a variety of networks and datasets, including ResNet-50, MobileNets on Imagenet-2012, and RNNs on WikiText-103. Finally, we provide some insights into why allowing the topology to change during the optimization can overcome local minima encountered when the topology remains static. Code used in our work can be found in github.com/google-research/rigl.
PDF Abstract ICML 2020 PDFCode





Datasets
 CIFAR-10
CIFAR-10
 ImageNet
ImageNet
 WikiText-2
WikiText-2
 WikiText-103
WikiText-103
Reproducibility Reports
We reproduce RigLʼs performance on CIFAR-10 within 0.1% of the reported value. On both CIFAR-10/100, the central claim holds—given a fixed training budget, RigL surpasses existing dynamic-sparse training methods over a range of target sparsities. By training longer, the performance can match or exceed iterative pruning, while consuming constant FLOPs throughout training. We also show that there is little benefit in tuning RigLʼs hyper-parameters for every sparsity, initialization pair—the reference choice of hyperparameters is often close to optimal performance. Going beyond the original paper, we find that the optimal initialization scheme depends on the training constraint. While the Erdos-Renyi-Kernel distribution outperforms Random distribution for a fixed parameter count, for a fixed FLOP count, the latter performs better. Finally, redistributing layer-wise sparsity while training can bridge the performance gap between the two initialization schemes, but increases computational cost.

