ROSITA: Refined BERT cOmpreSsion with InTegrAted techniques
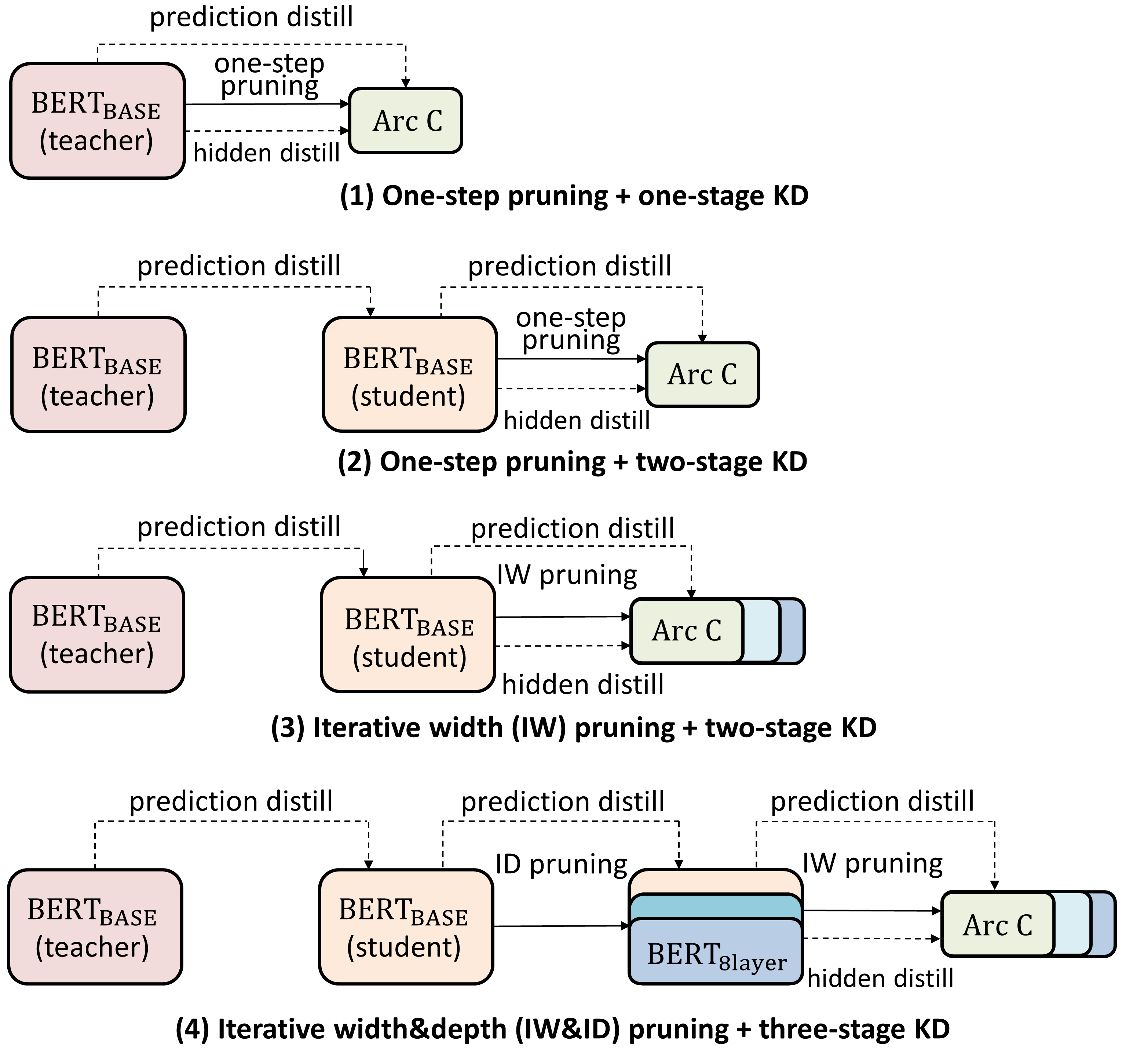
Pre-trained language models of the BERT family have defined the state-of-the-arts in a wide range of NLP tasks. However, the performance of BERT-based models is mainly driven by the enormous amount of parameters, which hinders their application to resource-limited scenarios. Faced with this problem, recent studies have been attempting to compress BERT into a small-scale model. However, most previous work primarily focuses on a single kind of compression technique, and few attention has been paid to the combination of different methods. When BERT is compressed with integrated techniques, a critical question is how to design the entire compression framework to obtain the optimal performance. In response to this question, we integrate three kinds of compression methods (weight pruning, low-rank factorization and knowledge distillation (KD)) and explore a range of designs concerning model architecture, KD strategy, pruning frequency and learning rate schedule. We find that a careful choice of the designs is crucial to the performance of the compressed model. Based on the empirical findings, our best compressed model, dubbed Refined BERT cOmpreSsion with InTegrAted techniques (ROSITA), is $7.5 \times$ smaller than BERT while maintains $98.5\%$ of the performance on five tasks of the GLUE benchmark, outperforming the previous BERT compression methods with similar parameter budget. The code is available at https://github.com/llyx97/Rosita.
PDF Abstract

 GLUE
GLUE
 QNLI
QNLI
