RuDaS: Synthetic Datasets for Rule Learning and Evaluation Tools
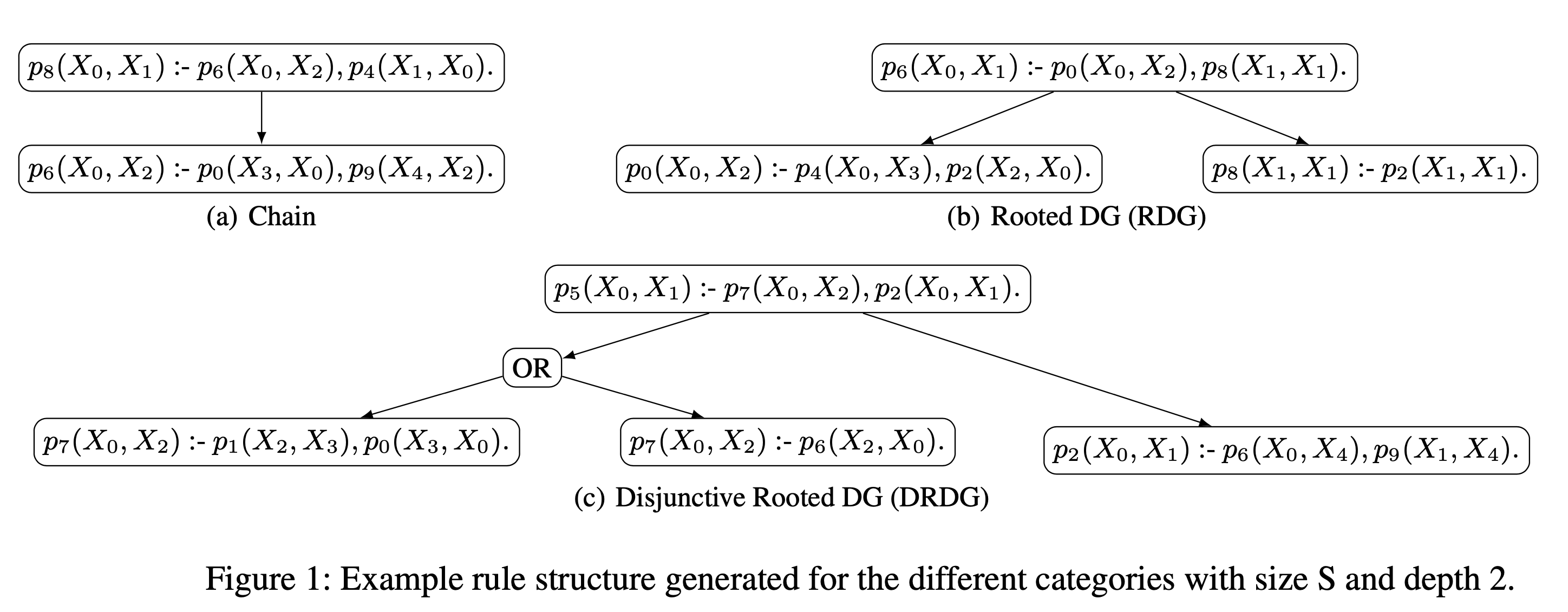
Logical rules are a popular knowledge representation language in many domains, representing background knowledge and encoding information that can be derived from given facts in a compact form. However, rule formulation is a complex process that requires deep domain expertise,and is further challenged by today's often large, heterogeneous, and incomplete knowledge graphs. Several approaches for learning rules automatically, given a set of input example facts,have been proposed over time, including, more recently, neural systems. Yet, the area is missing adequate datasets and evaluation approaches: existing datasets often resemble toy examples that neither cover the various kinds of dependencies between rules nor allow for testing scalability. We present a tool for generating different kinds of datasets and for evaluating rule learning systems, including new performance measures.
PDF AbstractCode

Datasets
Introduced in the Paper:
 RuDaS
RuDaS

