Rule-embedded network for audio-visual voice activity detection in live musical video streams
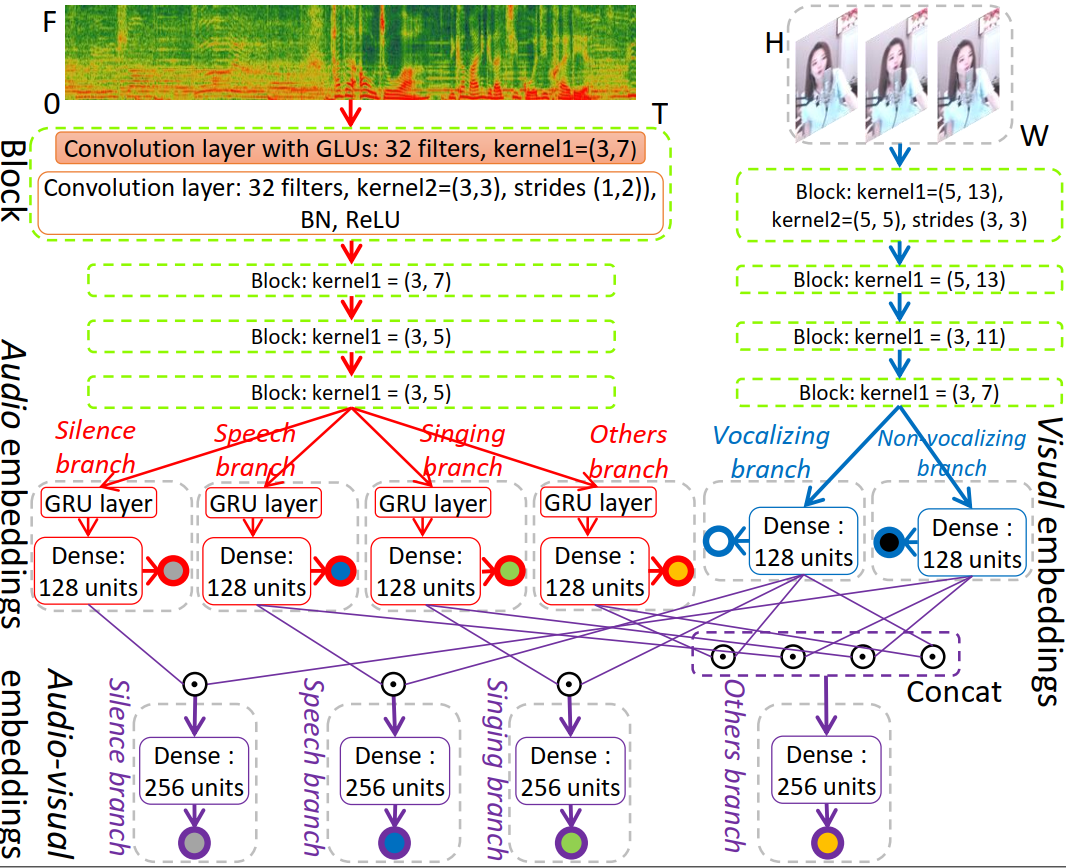
Detecting anchor's voice in live musical streams is an important preprocessing for music and speech signal processing. Existing approaches to voice activity detection (VAD) primarily rely on audio, however, audio-based VAD is difficult to effectively focus on the target voice in noisy environments. With the help of visual information, this paper proposes a rule-embedded network to fuse the audio-visual (A-V) inputs to help the model better detect target voice. The core role of the rule in the model is to coordinate the relation between the bi-modal information and use visual representations as the mask to filter out the information of non-target sound. Experiments show that: 1) with the help of cross-modal fusion by the proposed rule, the detection result of A-V branch outperforms that of audio branch; 2) the performance of bi-modal model far outperforms that of audio-only models, indicating that the incorporation of both audio and visual signals is highly beneficial for VAD. To attract more attention to the cross-modal music and audio signal processing, a new live musical video corpus with frame-level label is introduced.
PDF Abstract