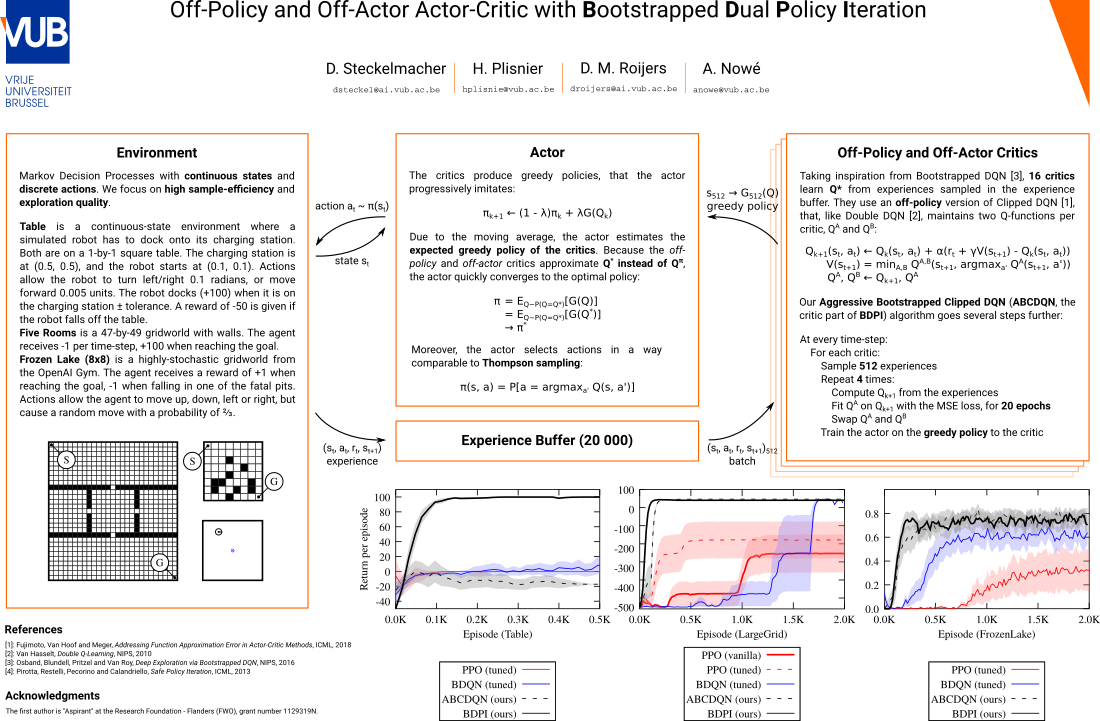
Sample-Efficient Model-Free Reinforcement Learning with Off-Policy Critics
Value-based reinforcement-learning algorithms provide state-of-the-art results in model-free discrete-action settings, and tend to outperform actor-critic algorithms. We argue that actor-critic algorithms are limited by their need for an on-policy critic. We propose Bootstrapped Dual Policy Iteration (BDPI), a novel model-free reinforcement-learning algorithm for continuous states and discrete actions, with an actor and several off-policy critics. Off-policy critics are compatible with experience replay, ensuring high sample-efficiency, without the need for off-policy corrections. The actor, by slowly imitating the average greedy policy of the critics, leads to high-quality and state-specific exploration, which we compare to Thompson sampling. Because the actor and critics are fully decoupled, BDPI is remarkably stable, and unusually robust to its hyper-parameters. BDPI is significantly more sample-efficient than Bootstrapped DQN, PPO, and ACKTR, on discrete, continuous and pixel-based tasks. Source code: https://github.com/vub-ai-lab/bdpi.
PDF Abstract

