Say As You Wish: Fine-grained Control of Image Caption Generation with Abstract Scene Graphs
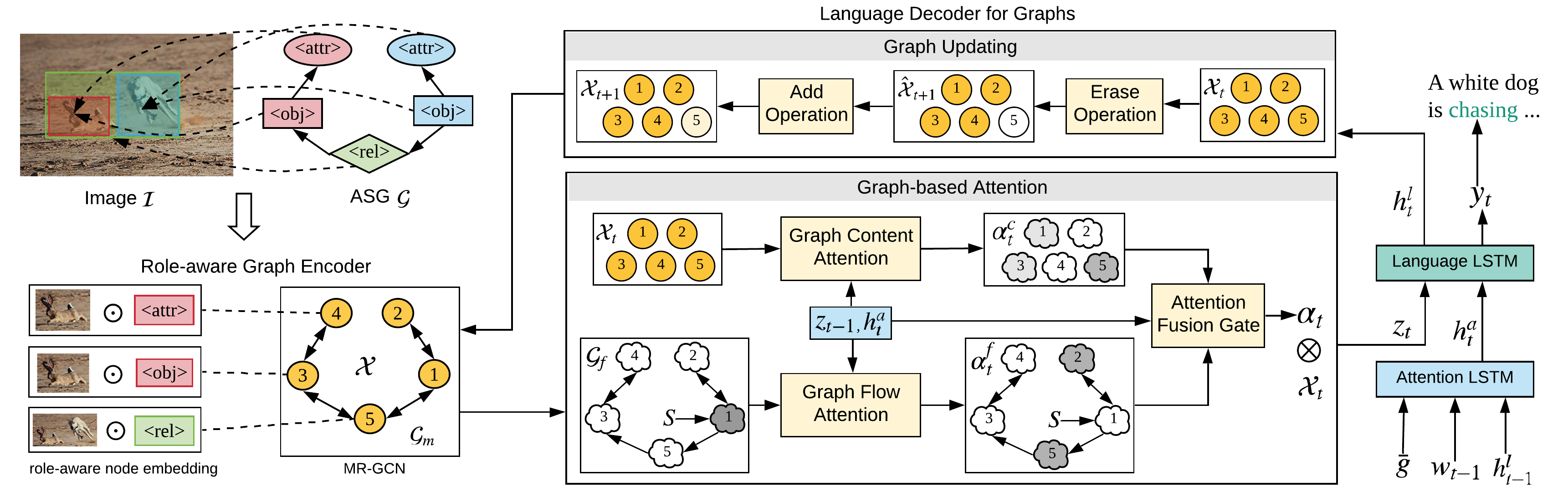
Humans are able to describe image contents with coarse to fine details as they wish. However, most image captioning models are intention-agnostic which can not generate diverse descriptions according to different user intentions initiatively. In this work, we propose the Abstract Scene Graph (ASG) structure to represent user intention in fine-grained level and control what and how detailed the generated description should be. The ASG is a directed graph consisting of three types of \textbf{abstract nodes} (object, attribute, relationship) grounded in the image without any concrete semantic labels. Thus it is easy to obtain either manually or automatically. From the ASG, we propose a novel ASG2Caption model, which is able to recognise user intentions and semantics in the graph, and therefore generate desired captions according to the graph structure. Our model achieves better controllability conditioning on ASGs than carefully designed baselines on both VisualGenome and MSCOCO datasets. It also significantly improves the caption diversity via automatically sampling diverse ASGs as control signals.
PDF Abstract CVPR 2020 PDF CVPR 2020 Abstract


 MS COCO
MS COCO
 Visual Genome
Visual Genome
