Scanning Only Once: An End-to-end Framework for Fast Temporal Grounding in Long Videos
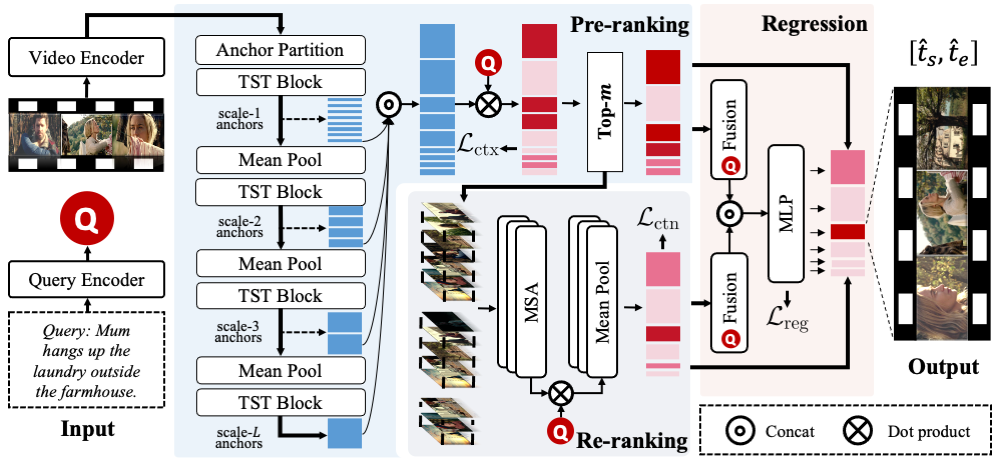
Video temporal grounding aims to pinpoint a video segment that matches the query description. Despite the recent advance in short-form videos (\textit{e.g.}, in minutes), temporal grounding in long videos (\textit{e.g.}, in hours) is still at its early stage. To address this challenge, a common practice is to employ a sliding window, yet can be inefficient and inflexible due to the limited number of frames within the window. In this work, we propose an end-to-end framework for fast temporal grounding, which is able to model an hours-long video with \textbf{one-time} network execution. Our pipeline is formulated in a coarse-to-fine manner, where we first extract context knowledge from non-overlapped video clips (\textit{i.e.}, anchors), and then supplement the anchors that highly response to the query with detailed content knowledge. Besides the remarkably high pipeline efficiency, another advantage of our approach is the capability of capturing long-range temporal correlation, thanks to modeling the entire video as a whole, and hence facilitates more accurate grounding. Experimental results suggest that, on the long-form video datasets MAD and Ego4d, our method significantly outperforms state-of-the-arts, and achieves \textbf{14.6$\times$} / \textbf{102.8$\times$} higher efficiency respectively. Project can be found at \url{https://github.com/afcedf/SOONet.git}.
PDF Abstract ICCV 2023 PDF ICCV 2023 Abstract
 MAD
MAD
