SceneEncoder: Scene-Aware Semantic Segmentation of Point Clouds with A Learnable Scene Descriptor
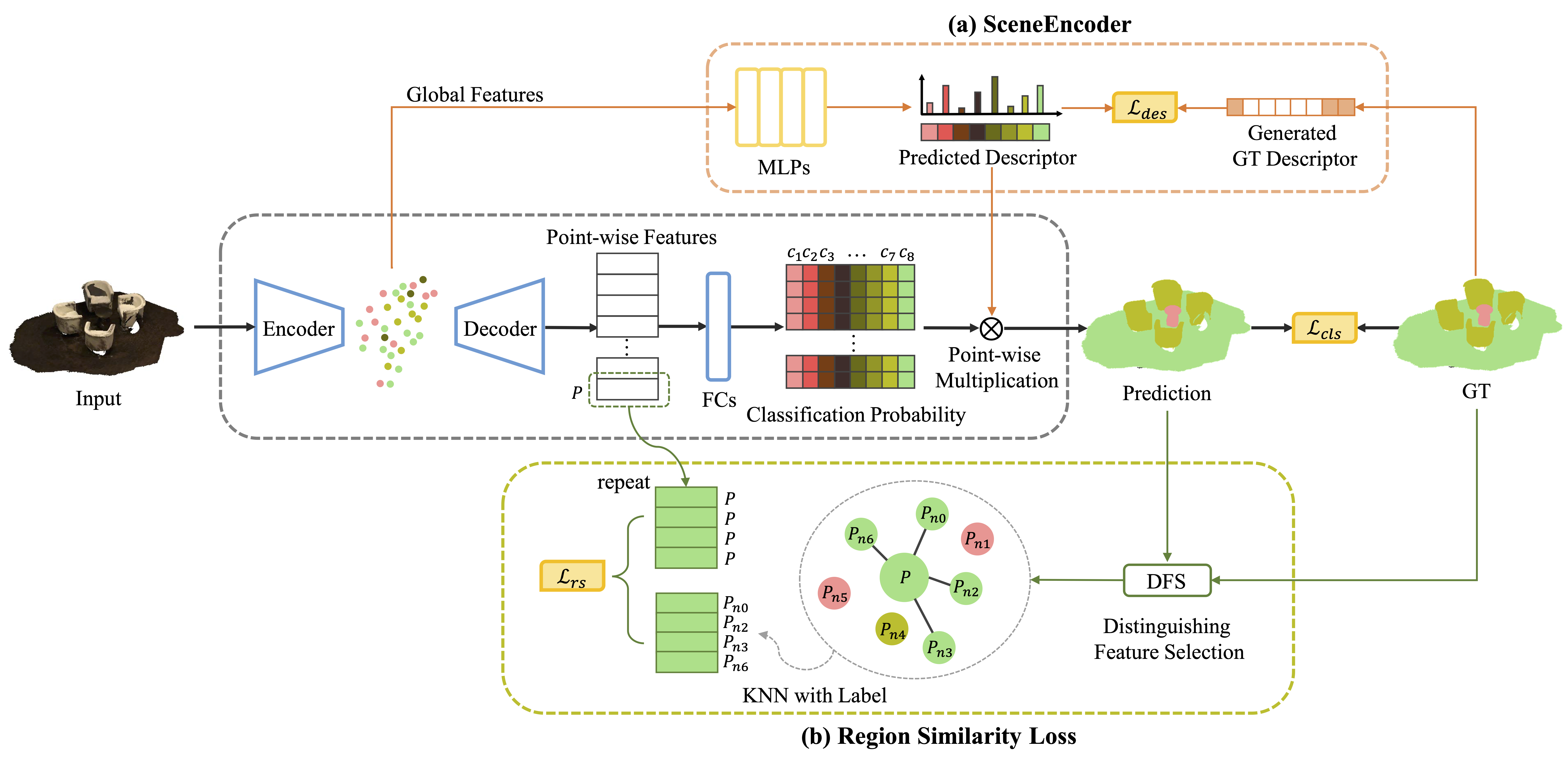
Besides local features, global information plays an essential role in semantic segmentation, while recent works usually fail to explicitly extract the meaningful global information and make full use of it. In this paper, we propose a SceneEncoder module to impose a scene-aware guidance to enhance the effect of global information. The module predicts a scene descriptor, which learns to represent the categories of objects existing in the scene and directly guides the point-level semantic segmentation through filtering out categories not belonging to this scene. Additionally, to alleviate segmentation noise in local region, we design a region similarity loss to propagate distinguishing features to their own neighboring points with the same label, leading to the enhancement of the distinguishing ability of point-wise features. We integrate our methods into several prevailing networks and conduct extensive experiments on benchmark datasets ScanNet and ShapeNet. Results show that our methods greatly improve the performance of baselines and achieve state-of-the-art performance.
PDF Abstract


 ShapeNet
ShapeNet
 ScanNet
ScanNet
