Seeing wake words: Audio-visual Keyword Spotting
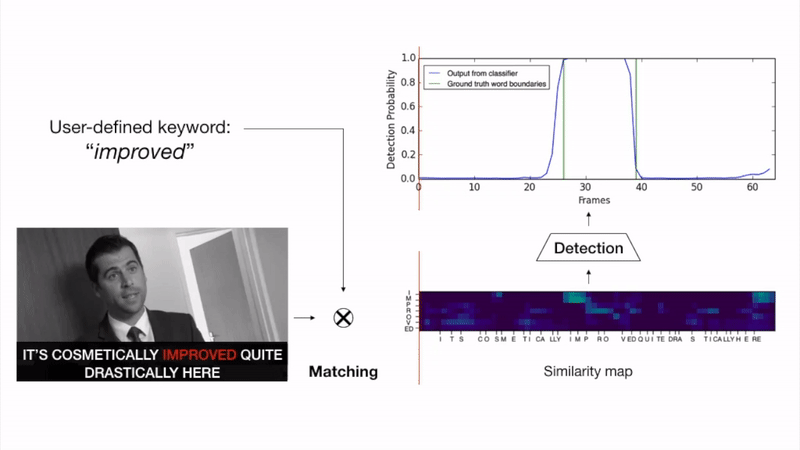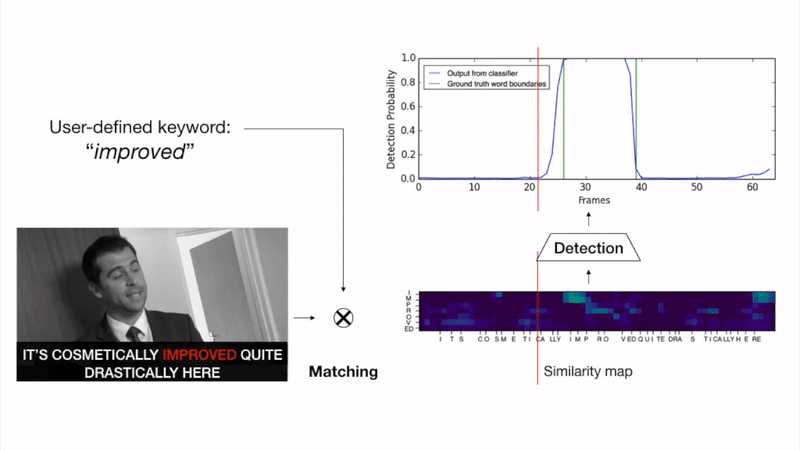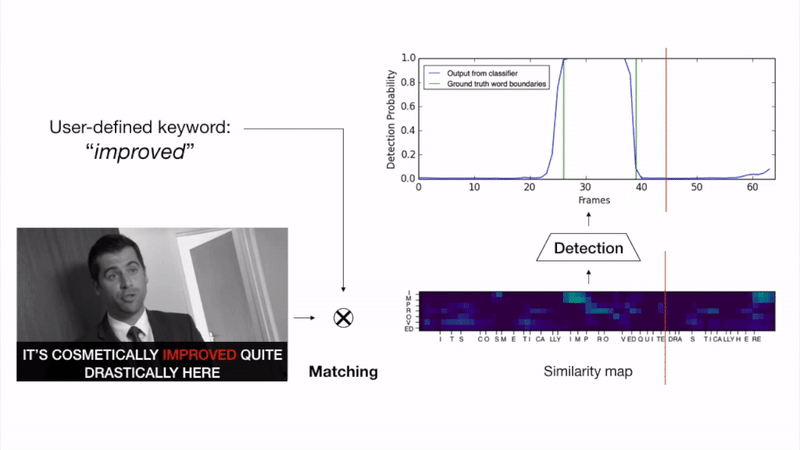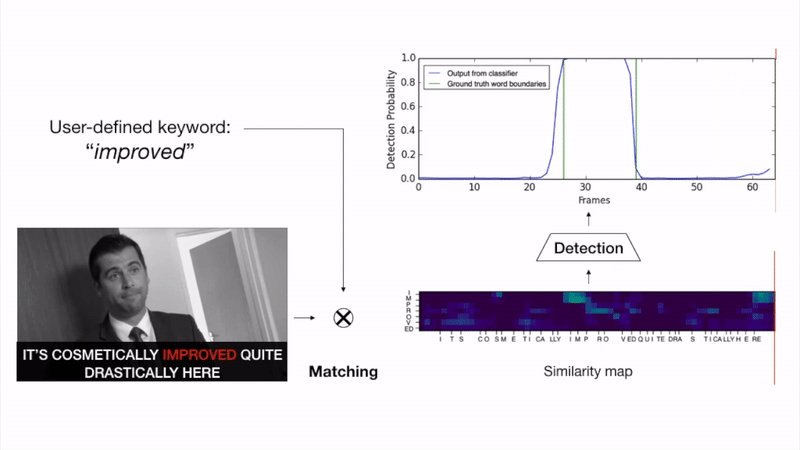
The goal of this work is to automatically determine whether and when a word of interest is spoken by a talking face, with or without the audio. We propose a zero-shot method suitable for in the wild videos. Our key contributions are: (1) a novel convolutional architecture, KWS-Net, that uses a similarity map intermediate representation to separate the task into (i) sequence matching, and (ii) pattern detection, to decide whether the word is there and when; (2) we demonstrate that if audio is available, visual keyword spotting improves the performance both for a clean and noisy audio signal. Finally, (3) we show that our method generalises to other languages, specifically French and German, and achieves a comparable performance to English with less language specific data, by fine-tuning the network pre-trained on English. The method exceeds the performance of the previous state-of-the-art visual keyword spotting architecture when trained and tested on the same benchmark, and also that of a state-of-the-art lip reading method.
PDF Abstract


 LRW
LRW
 LRS2
LRS2
