Segatron: Segment-Aware Transformer for Language Modeling and Understanding
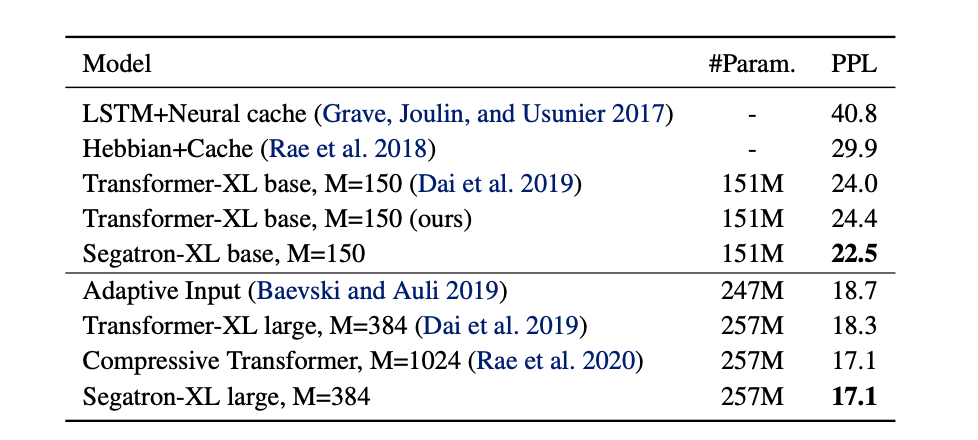
Transformers are powerful for sequence modeling. Nearly all state-of-the-art language models and pre-trained language models are based on the Transformer architecture. However, it distinguishes sequential tokens only with the token position index. We hypothesize that better contextual representations can be generated from the Transformer with richer positional information. To verify this, we propose a segment-aware Transformer (Segatron), by replacing the original token position encoding with a combined position encoding of paragraph, sentence, and token. We first introduce the segment-aware mechanism to Transformer-XL, which is a popular Transformer-based language model with memory extension and relative position encoding. We find that our method can further improve the Transformer-XL base model and large model, achieving 17.1 perplexity on the WikiText-103 dataset. We further investigate the pre-training masked language modeling task with Segatron. Experimental results show that BERT pre-trained with Segatron (SegaBERT) can outperform BERT with vanilla Transformer on various NLP tasks, and outperforms RoBERTa on zero-shot sentence representation learning.
PDF Abstract



 GLUE
GLUE
 QNLI
QNLI
 WikiText-2
WikiText-2
 WikiText-103
WikiText-103

