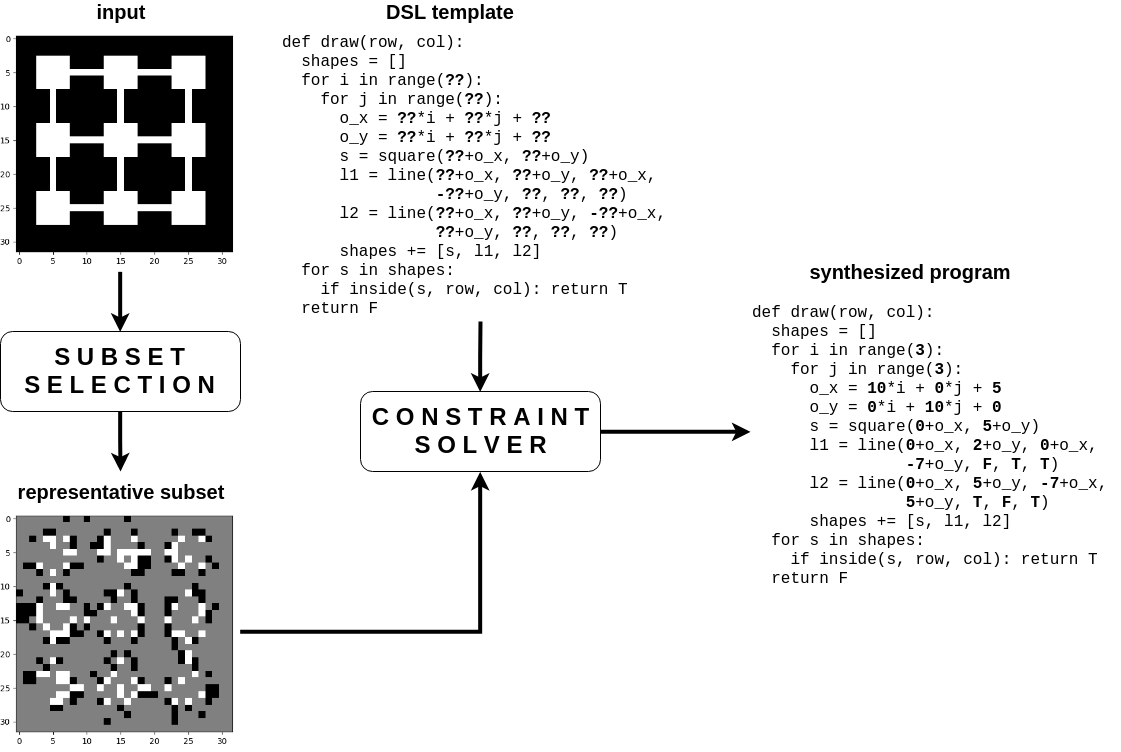
Selecting Representative Examples for Program Synthesis
Program synthesis is a class of regression problems where one seeks a solution, in the form of a source-code program, mapping the inputs to their corresponding outputs exactly. Due to its precise and combinatorial nature, program synthesis is commonly formulated as a constraint satisfaction problem, where input-output examples are encoded as constraints and solved with a constraint solver. A key challenge of this formulation is scalability: while constraint solvers work well with a few well-chosen examples, a large set of examples can incur significant overhead in both time and memory. We describe a method to discover a subset of examples that is both small and representative: the subset is constructed iteratively, using a neural network to predict the probability of unchosen examples conditioned on the chosen examples in the subset, and greedily adding the least probable example. We empirically evaluate the representativeness of the subsets constructed by our method, and demonstrate such subsets can significantly improve synthesis time and stability.
PDF Abstract ICML 2018 PDF ICML 2018 Abstract

