Self-Adaptive Training: beyond Empirical Risk Minimization
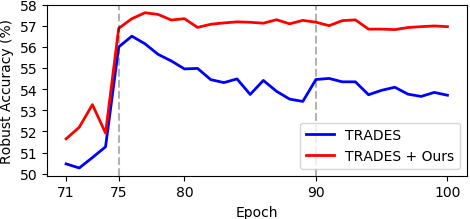
We propose self-adaptive training---a new training algorithm that dynamically corrects problematic training labels by model predictions without incurring extra computational cost---to improve generalization of deep learning for potentially corrupted training data. This problem is crucial towards robustly learning from data that are corrupted by, e.g., label noises and out-of-distribution samples. The standard empirical risk minimization (ERM) for such data, however, may easily overfit noises and thus suffers from sub-optimal performance. In this paper, we observe that model predictions can substantially benefit the training process: self-adaptive training significantly improves generalization over ERM under various levels of noises, and mitigates the overfitting issue in both natural and adversarial training. We evaluate the error-capacity curve of self-adaptive training: the test error is monotonously decreasing w.r.t. model capacity. This is in sharp contrast to the recently-discovered double-descent phenomenon in ERM which might be a result of overfitting of noises. Experiments on CIFAR and ImageNet datasets verify the effectiveness of our approach in two applications: classification with label noise and selective classification. We release our code at https://github.com/LayneH/self-adaptive-training.
PDF Abstract NeurIPS 2020 PDF NeurIPS 2020 Abstract

 CIFAR-10
CIFAR-10
 ImageNet
ImageNet
 CIFAR-100
CIFAR-100
