Self-Adaptive Training: Bridging Supervised and Self-Supervised Learning
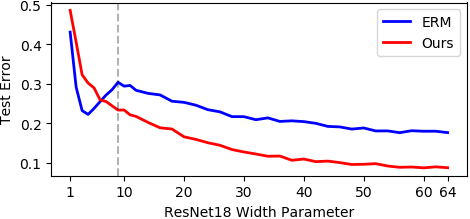
We propose self-adaptive training -- a unified training algorithm that dynamically calibrates and enhances training processes by model predictions without incurring an extra computational cost -- to advance both supervised and self-supervised learning of deep neural networks. We analyze the training dynamics of deep networks on training data that are corrupted by, e.g., random noise and adversarial examples. Our analysis shows that model predictions are able to magnify useful underlying information in data and this phenomenon occurs broadly even in the absence of any label information, highlighting that model predictions could substantially benefit the training processes: self-adaptive training improves the generalization of deep networks under noise and enhances the self-supervised representation learning. The analysis also sheds light on understanding deep learning, e.g., a potential explanation of the recently-discovered double-descent phenomenon in empirical risk minimization and the collapsing issue of the state-of-the-art self-supervised learning algorithms. Experiments on the CIFAR, STL, and ImageNet datasets verify the effectiveness of our approach in three applications: classification with label noise, selective classification, and linear evaluation. To facilitate future research, the code has been made publicly available at https://github.com/LayneH/self-adaptive-training.
PDF Abstract


 CIFAR-10
CIFAR-10
 ImageNet
ImageNet
 CIFAR-100
CIFAR-100
 SVHN
SVHN
 STL-10
STL-10
